AES-GCM과 VAES 인스트럭션
배경
인터넷에서 쓰는 블록 암호 동작 방식으로 이전에는 CBC가 대세였지만 지금은 GCM이 그 자리를 차지했다. 당장 이 사이트의 TLS 연결 정보를 확인해 봐도 (특이한 클라이언트가 아니라면) 암호 스위트가 TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256이라고 나온다. 그리고 TLS뿐 아니라 IPsec에서도 GCM 모드가 자리를 잡고 있다.
TLS를 포함한 여러 암호 응용들에서는 내용이 같은 평문 블록을 암호화 한 결과가 다른 게 좋다. 두 데이터 덩어리의 내용이 같다는 정보 자체가 내용을 추측하는 데 쓰일 수 있기 때문이다. 그래서 첫 블록을 암호화 할 때 난수 IV를 입력해 주고 이후 블록을 암호화 할 때도 입력에 뭔가 난수스러운 요소를 더해 준다. CBC(Cipher Block Chaining)에서는 그 이름처럼 암호화 한 블록을 다음 평문 블록에 XOR로 연결시킨다.
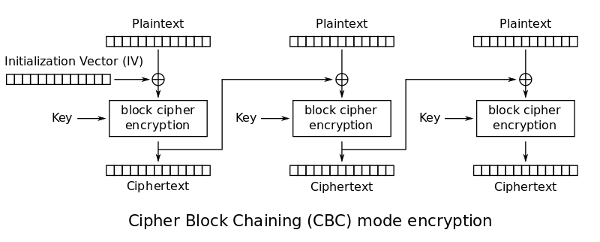
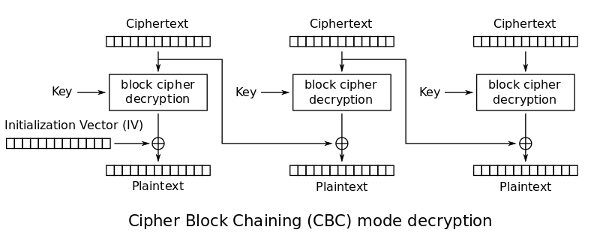
성능 측면에서 CBC의 단점은 병렬 처리가 안 된다는 점이다. 한 블록을 암호화 하려면 바로 앞 블록을 암호화 한 결과가 필요하기 때문이다. (반면 복호화는 병렬로 진행할 수 있다.)
GCM(Galois/Counter Mode)은 이름처럼 카운터(CTR) 모드에 인증/무결성을 위한 연산을 더한 것이며 AEAD에 잘 어울린다. GCM에서 암호화 부분인 CTR 모드를 보면,
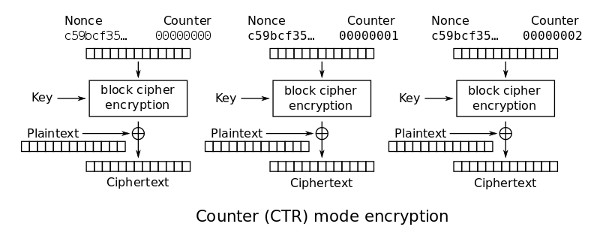
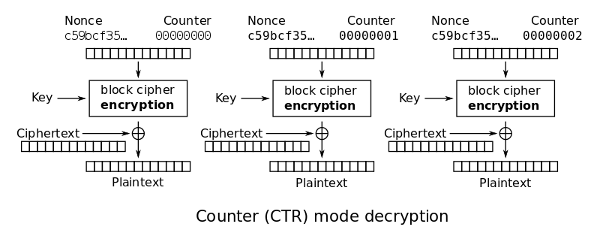
어랏, 블록 암호 안에 스트림 암호가 숨어 있다. 키스트림을 생성해서 평문과 XOR 하면 암호화고, 그 결과를 같은 키스트림과 다시 XOR 하면 복호화다. 그림을 보면 알 수 있듯 다른 블록과 상관없이 각 블록을 단독으로 암호화 할 수 있고, 그래서 병렬 처리가 가능하다.
VAES 인스트럭션 세트
근데 여러 블록을 병렬로 처리한다는 게 말이 쉽지 저절로 가능한 건 아니다. 전용 암호 가속 장치를 만드는 경우라면 내부에 AES 모듈을 여러 개 집어넣어서 병렬 처리를 하도록 하면 될 거다. 하지만 AES-NI 정도나 쓰는 환경에서는 병렬 처리를 소프트웨어로 구현해야 할 텐데, 암호화 할 메시지 일부를 이웃 코어에게 부탁하고 그 결과를 다시 받아오는 건 얼핏 생각해 봐도 오버헤드가 무시무시하다. 한편으로 요즘 x86 계열 CPU에서는 다들 AES 인스트럭션 세트를 지원하고 하니까 CPU에서 요래요래 병렬 처리를 해 주면 참 좋을 거다.
그래서 등장! AES-NI를 AVX-512에 걸맞게 확장한 VAES! 한번에 2블록씩, 심지어 4블록씩 쾌속 연산!
사소한 문제라면 VAES 인스트럭션 세트를 지원하는 Ice Lake 아키텍처가 아직 출시되지 않았다는 건데, 뭐, 사소하다. 아직 사용할 수 없는 VAES 인스트럭션을 연구하고 싶던 이들은 “Making AES great again”이라는 (어느 대통령을 떠올리지 말자.) 논문에서 에뮬레이터로 성능을 측정했다. 파이프라이닝 기법까지 더해서 결론에서 내놓는 수치는 무려 0.16 clock per byte이다.
미래의 흔적
근데 암호 관련 라이브러리들의 소스 코드를 보면 앞에 “v”가 붙은 인스트럭션을 벌써 쓰고 있다. Ice Lake 출시를 대비해서 미리 코드를 짜 놓은 걸까?
GnuTLS aesni-gcm-x86_64.s:
.Lresume_ctr32:
...
vaesenc %xmm2,%xmm9,%xmm9
vmovdqu 48+8(%rsp),%xmm0
vpxor %xmm15,%xmm13,%xmm13
vpclmulqdq $0x00,%xmm3,%xmm7,%xmm1
vaesenc %xmm2,%xmm10,%xmm10
vpxor %xmm15,%xmm14,%xmm14
setnc %r12b
vpclmulqdq $0x11,%xmm3,%xmm7,%xmm7
vaesenc %xmm2,%xmm11,%xmm11
...
그럴 리 없다. 위 코드에 등장하는 VAESENC 인스트럭션은 AVX-512의 전전 버전인 AVX에서 슬쩍 등장한 녀석이다. 그래서 피연산자로 128비트 레지스터(%xmmN)만 쓸 수 있고 %ymmN이나 %zmmN은 못 쓴다. 원래 AES-NI의 AESENC 인스트럭션도 %xmmN 레지스터를 쓰니까 결국 피연산자 개수가 하나 늘었을 뿐이다. 인텔 매뉴얼 참고.
