연결 리스트들의 긴 목록

리눅스 커널에는 연결 리스트 구현이 있다. 그것도 다양하게. 몇 가지를 살펴보자.
기본
첫 번째가 뭔지는 정해져 있다.
struct list_head {
struct list_head *next, *prev;
};
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
...
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_head within the struct.
*/
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
...
/**
* list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
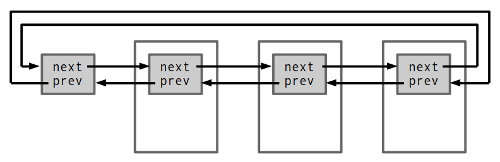
원형 이중 연결 리스트다. 노드에서 데이터를 가리키는 게 아니라 데이터에 노드가 들어간다. 노드가 주어지면 데이터를 얻을 수 있다는 점에선 동등하며 참조를 표현하는 다른 방식일 뿐이다. 그런데 그 작은 차이가 메모리 할당 횟수를 줄일 수 있다. (내장 방식으로는 여러 노드가 한 데이터를 가리키는 걸 표현하는 데 제약이 있다는 차이가 있기는 하다. 하지만 흔히 만나는 경우는 아니다.)
데이터 타입에 list_head를 내장시키지 못하는데 리스트 API는 이용하고 싶다면 좀 간접적인 방식을 쓸 수 있다.
struct bpf_prog_list {
struct list_head node;
struct bpf_prog *prog;
};
list.h 파일을 살펴보면 비슷한 리스트가 하나 더 있다.
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
};
#define HLIST_HEAD_INIT { .first = NULL }
#define HLIST_HEAD(name) struct hlist_head name = { .first = NULL }
#define INIT_HLIST_HEAD(ptr) ((ptr)->first = NULL)
static inline void INIT_HLIST_NODE(struct hlist_node *h)
{
h->next = NULL;
h->pprev = NULL;
}
...
static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h)
{
struct hlist_node *first = h->first;
n->next = first;
if (first)
first->pprev = &n->next;
WRITE_ONCE(h->first, n);
n->pprev = &h->first;
}
...
#define hlist_for_each(pos, head) \
for (pos = (head)->first; pos ; pos = pos->next)
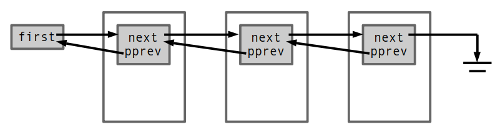
pprev는 앞 노드의 next(또는 first) 필드를 가리키는데, 실제 들어가는 주소 값을 놓고 보면 list_head의 prev와 다를 게 없다. 그래서 여전히 O(1)으로 노드 삽입/제거가 가능하고 원하면 역방향 순회도 가능하다. 원형이 아니라서 생기는 몇 가지 차이를 빼면 다른 게 딱히 없는데도 별도로 타입이 있는 건 hlist_head 크기가 절반이기 때문이다. 해시 테이블에서 체인 배열이 잡아먹는 메모리가 절반이라는 얘기고, 그래서 이름에 “h”가 들어가 있다.
사용자 공간에도 비슷한 구현이 있다. BSD에서 온 건데, list가 CIRCLEQ에 대응하고 hlist가 LIST에 대응한다. 그리고 좀 아래 나오는 llist가 SLIST에 대응한다. 리눅스 커널 구현과 비슷하면서도 좀 불편하다.
락! 비트!
커널에서 동시 접근은 일상이고, 그래서 연결 리스트에 락이 딸린 경우가 많다.
struct wait_queue_head {
spinlock_t lock;
struct list_head head;
};
길이까지 딸려 있기도 하다.
struct sk_buff_head {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
__u32 qlen;
spinlock_t lock;
};
...
struct sk_buff {
union {
struct {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
...
};
struct rb_node rbnode; /* used in netem & tcp stack */
};
...
};
그런데 해시 테이블에서는 락을 어디에 추가해야 할까? 테이블 전체에 락 한 개를 쓰자니 동시성이 떨어질 것 같다. 그렇다고 체인별로 락을 쓰자니 추가 메모리가 부담이다. 근데 hlist_head 구조체를 가만히 들여다보니 락을 집어넣을 공간이 좀 있다. 그래서 나온 게 hlist_bl이다. (상상하는 그 BL이 아니다. bit lock이다.)
/*
* Special version of lists, where head of the list has a lock in the lowest
* bit. This is useful for scalable hash tables without increasing memory
* footprint overhead.
* ...
*/
#if defined(CONFIG_SMP) || defined(CONFIG_DEBUG_SPINLOCK)
#define LIST_BL_LOCKMASK 1UL
#else
#define LIST_BL_LOCKMASK 0UL
#endif
...
struct hlist_bl_head {
struct hlist_bl_node *first;
};
struct hlist_bl_node {
struct hlist_bl_node *next, **pprev;
};
...
static inline struct hlist_bl_node *hlist_bl_first(struct hlist_bl_head *h)
{
return (struct hlist_bl_node *)
((unsigned long)h->first & ~LIST_BL_LOCKMASK);
}
static inline void hlist_bl_set_first(struct hlist_bl_head *h,
struct hlist_bl_node *n)
{
LIST_BL_BUG_ON((unsigned long)n & LIST_BL_LOCKMASK);
LIST_BL_BUG_ON(((unsigned long)h->first & LIST_BL_LOCKMASK) !=
LIST_BL_LOCKMASK);
h->first = (struct hlist_bl_node *)((unsigned long)n | LIST_BL_LOCKMASK);
}
...
static inline void hlist_bl_lock(struct hlist_bl_head *b)
{
bit_spin_lock(0, (unsigned long *)b);
}
static inline void hlist_bl_unlock(struct hlist_bl_head *b)
{
__bit_spin_unlock(0, (unsigned long *)b);
}
메모리 상의 hlist_bl_node 객체 주소에서 최하위 비트가 항상 0이라고 가정하는 건데, 정상적인 방식으로 메모리를 할당해서 쓴다면 안심해도 된다.
비트를 가지고 노는 리스트가 또 있다. hlist에서 리스트 끝을 나타내는 데 일부 비트만으로 충분하다면 나머지 비트들에 유용한 값을 저장할 수 있다.
/*
* Special version of lists, where end of list is not a NULL pointer,
* but a 'nulls' marker, which can have many different values.
* (up to 2^31 different values guaranteed on all platforms)
*
* In the standard hlist, termination of a list is the NULL pointer.
* In this special 'nulls' variant, we use the fact that objects stored in
* a list are aligned on a word (4 or 8 bytes alignment).
* We therefore use the last significant bit of 'ptr' :
* Set to 1 : This is a 'nulls' end-of-list marker (ptr >> 1)
* Set to 0 : This is a pointer to some object (ptr)
*/
struct hlist_nulls_head {
struct hlist_nulls_node *first;
};
struct hlist_nulls_node {
struct hlist_nulls_node *next, **pprev;
};
#define NULLS_MARKER(value) (1UL | (((long)value) << 1))
#define INIT_HLIST_NULLS_HEAD(ptr, nulls) \
((ptr)->first = (struct hlist_nulls_node *) NULLS_MARKER(nulls))
#define hlist_nulls_entry(ptr, type, member) container_of(ptr,type,member)
#define hlist_nulls_entry_safe(ptr, type, member) \
({ typeof(ptr) ____ptr = (ptr); \
!is_a_nulls(____ptr) ? hlist_nulls_entry(____ptr, type, member) : NULL; \
})
static inline int is_a_nulls(const struct hlist_nulls_node *ptr)
{
return ((unsigned long)ptr & 1);
}
static inline unsigned long get_nulls_value(const struct hlist_nulls_node *ptr)
{
return ((unsigned long)ptr) >> 1;
}
리스트 끝에 63비트나 31비트짜리 값을 저장할 수 있대도 그걸 어디 써먹는가 싶겠지만 “rcu”가 붙은 (아래에서 설명할) 버전을 넷필터 conntrack 모듈에서 쓴다. 체인 순회를 하는 중에 누가 노드를 다른 체인으로 슬쩍 옮긴 경우에 (그래서 다른 체인에서 순회가 끝난 경우에) 원래 체인을 처음부터 다시 순회하게 되는데, 리스트 끝에 체인 번호를 저장해서 순회를 시작했던 체인이 맞는지 확인한다.
net/netfilter/nf_conntrack_core.c:
static struct nf_conntrack_tuple_hash *
____nf_conntrack_find(struct net *net, const struct nf_conntrack_zone *zone,
const struct nf_conntrack_tuple *tuple, u32 hash)
{
struct nf_conntrack_tuple_hash *h;
struct hlist_nulls_head *ct_hash;
struct hlist_nulls_node *n;
unsigned int bucket, hsize;
begin:
nf_conntrack_get_ht(&ct_hash, &hsize);
bucket = reciprocal_scale(hash, hsize);
hlist_nulls_for_each_entry_rcu(h, n, &ct_hash[bucket], hnnode) {
...
if (nf_ct_key_equal(h, tuple, zone, net))
return h;
}
/*
* if the nulls value we got at the end of this lookup is
* not the expected one, we must restart lookup.
* We probably met an item that was moved to another chain.
*/
if (get_nulls_value(n) != bucket) {
NF_CT_STAT_INC_ATOMIC(net, search_restart);
goto begin;
}
return NULL;
}
hlist_bl은 머리에 락을 추가하는 것이고 hlist_nulls는 꼬리에 값을 추가하는 것이니 둘을 합칠 수도 있을 거다. 하지만 현재 list_bl_nulls 같은 건 없다.
프로세스를 위한 리스트
선점이 없다면 스핀락으로 충분하다. 하지만 프로세스 문맥에서도 리스트는 써야 된다.
간단하게는 스핀락 대신 세마포어를 쓸 수 있다. 하지만 접근을 좀 더 정밀하게 제어해서 동시성을 높이고 싶을 때가 있다. 그럴 때는 객체 자체에 대한 접근과 객체 간 연결(즉 리스트 구조)에 대한 접근을 나눠서 다뤄 볼 수 있다.
리스트 구조에 대한 접근은 단순하니까 스핀락 하나로 충분하다. 개별 객체에 대한 적절한 접근 제어 방식은 응용에 따라 다르겠지만 일단 락을 잡고 있는 시간이 매우 길 수도 있다는 건 분명하고, 그렇다면 참조 카운트 정도는 대부분 경우에서 유용할 거다.
한편으로 한 프로세스에서 리스트를 (순방향 또는 역방향으로) 순회하다가 어떤 노드를 잡은 채 잠들었는데 다른 프로세스에서 그 노드를 리스트에서 제거하려 한다고 해 보자. 그리고 잠들었던 프로세스가 깨어났을 때 나머지 노드들을 마저 순회할 수 있게 하고 싶다. 어떻게 해야 할까?
노드를 (prev와 next를 건드리지 않고) 쏙 빼내고 앞뒤의 노드들끼리 서로 연결해 주면 될까? 안 된다. 순회 프로세스가 깨어났을 때 그 앞뒤 노드들이 여전히 존재한다는 보장이 없다. 그렇다면 삭제하려는 노드를 다른 프로세스가 참조 중인 경우 삭제 표시만 해뒀다가 나중에 참조 카운트가 0으로 내려갈 때 실제 제거를 할 수 있다. 그리고 순회 과정에서 삭제 표시가 된 노드를 만나면 존재하지 않는 것처럼 다루면 되는데, 이걸 매번 직접 코딩 하기는 귀찮으니까 이터레이터가 제공되면 좋을 거다.
이 모든 걸 모은 게 klist다.
struct klist {
spinlock_t k_lock;
struct list_head k_list;
void (*get)(struct klist_node *);
void (*put)(struct klist_node *);
} __attribute__ ((aligned (sizeof(void *))));
#define KLIST_INIT(_name, _get, _put) \
{ .k_lock = __SPIN_LOCK_UNLOCKED(_name.k_lock), \
.k_list = LIST_HEAD_INIT(_name.k_list), \
.get = _get, \
.put = _put, }
#define DEFINE_KLIST(_name, _get, _put) \
struct klist _name = KLIST_INIT(_name, _get, _put)
extren void klist_init(struct klist *k, void (*get)(struct klist_node *),
void (*put)(struct klist_node *));
struct klist_node {
void *n_klist; /* never access directly */
struct list_head n_node;
struct kref n_ref;
};
extern void klist_add_tail(struct klist_node *n, struct klist *k);
...
struct klist_iter {
struct klist *i_klist;
struct klist_node *i_cur;
};
extern void klist_iter_init(struct klist *k, struct klist_iter *i);
extern void klist_iter_init_node(struct klist *k, struct klist_iter *i,
struct klist_node *n);
extern void klist_iter_exit(struct klist_iter *i);
extern struct klist_node *klist_prev(struct klist_iter *i);
extern struct klist_node *klist_next(struct klist_iter *i);
리스트를 보호하는 락(k_lock)과 노드별 참조 카운트(n_ref)가 있고 순회 API도 있다. 리스트에서 노드가 삽입/삭제될 때 호출되는 콜백 get()/put()을 등록해서 거기서 자원 할당/해제를 할 수도 있다. 삭제 표시에는 hlist_bl에서처럼 최하위 비트를 쓴다.
/*
* Use the lowest bit of n_klist to mark deleted nodes and exclude
* dead ones from iteration.
*/
#define KNODE_DEAD 1LU
#define KNODE_KLIST_MASK ~KNODE_DEAD
static struct klist *knode_klist(struct klist_node *knode)
{
return (struct klist *)
((unsigned long)knode->n_klist & KNODE_KLIST_MASK);
}
static bool knode_dead(struct klist_node *knode)
{
return (unsigned long)knode->n_klist & KNODE_DEAD;
}
static void knode_set_klist(struct klist_node *knode, struct klist *klist)
{
knode->n_klist = klist;
/* no knode deserves to start its life dead */
WARN_ON(knode_dead(knode));
}
static void knode_kill(struct klist_node *knode)
{
/* and no knode should die twice ever either, see we're very humane */
WARN_ON(knode_dead(knode));
*(unsigned long *)&knode->n_klist |= KNODE_DEAD;
}
...
static void klist_put(struct klist_node *n, bool kill)
{
struct klist *k = knode_klist(n);
void (*put)(struct klist_node *) = k->put;
spin_lock(&k->k_lock);
if (kill)
knode_kill(n);
if (!klist_dec_and_del(n))
put = NULL;
spin_unlock(&k->k_lock);
if (put)
put(n);
}
void klist_del(struct klist_node *n)
{
klist_put(n, true);
}
...
struct klist_node *klist_next(struct klist_iter *i)
{
...
spin_lock_irqsave(&i->i_klist->k_lock, flags);
...
i->i_cur = NULL;
while (next != to_klist_node(&i->i_klist->k_list)) {
if (likely(!knode_dead(next))) {
kref_get(&next->n_ref);
i->i_cur = next;
break;
}
next = to_klist_node(next->n_node.next);
}
spin_unlock_irqrestore(&i->i_klist->k_lock, flags);
if (put && last)
put(last);
return i->i_cur;
}
다시 단순하게
락, 비트… 번잡하다.
필요한 게 그저 단순한 큐라면 어떨까? 생산자와 소비자가 좀 있고 몇 가지 단순한 연산만 제공하면 된다면 말이다. 노드 연결은 단방향으로도 충분할 거다. 그리고 compare-and-swap 인스트럭션을 잘 이용하면 락 없는 구현이 가능하다.
/*
* Lock-less NULL terminated single linked list
*
* ...
*
* This can be summarized as follows:
*
* | add | del_first | del_all
* add | - | - | -
* del_first | | L | L
* del_all | | | -
*
* Where, a particular row's operation can happen concurrently with a column's
* operation, with "-" being no lock needed, while "L" being lock is needed.
*
* ...
*/
struct llist_head {
struct llist_node *first;
};
struct llist_node {
struct llist_node *next;
};
...
static inline bool llist_add(struct llist_node *new, struct llist_head *head)
{
return llist_add_batch(new, new, head);
}
static inline struct llist_node *llist_del_all(struct llist_head *head)
{
return xchg(&head->first, NULL);
}
bool llist_add_batch(struct llist_node *new_first, struct llist_node *new_last,
struct llist_head *head)
{
struct llist_node *first;
do {
new_last->next = first = READ_ONCE(head->first);
} while (cmpxchg(&head->first, first, new_first) != first);
return !first;
}
/**
* ...
*
* Only one llist_del_first user can be used simultaneously with
* multiple llist_add users without lock. Because otherwise
* llist_del_first, llist_add, llist_add (or llist_del_all, llist_add,
* llist_add) sequence in another user may change @head->first->next,
* but keep @head->first. If multiple consumers are needed, please
* use llist_del_all or use lock between consumers.
*/
struct llist_node *llist_del_first(struct llist_head *head)
{
struct llist_node *entry, *old_entry, *next;
entry = smp_load_acquire(&head->first);
for (;;) {
if (entry == NULL)
return NULL;
old_entry = entry;
next = READ_ONCE(entry->next);
entry = cmpxchg(&head->first, old_entry, next);
if (entry == old_entry)
break;
}
return entry;
}
머리에 추가하고 머리에서 빼내니까 사실은 스택, 좀 더 엄밀하게는 unbounded multi-producer multi-consumer 스택이다. 리스트를 뒤집어 주는 llist_reverse()가 있으니 경우에 따라 FIFO로 쓸 수도 있다.
스핀락이나 CAS 인스트럭션이나 바쁜 대기 방식인 건 마찬가지다. 그럼에도 CAS가 의미가 있는 건 버스를 잠그지 않을 수도 있다는 점이다. 한편으로 위 표에서 del_first()와 del_all()이 함께 동작할 때 락이 추가로 필요하다고 돼 있는 건 ABA 문제 때문이다. 락 없는 알고리즘은 멋지지만 이래저래 제한이 많다.
사실 진짜 FIFO는 따로 있다. 메모리 배리어만으로 구현돼 있으며 생산자와 소비자가 하나씩일 때는 락이 필요치 않다. 여러 드라이버에서 사용한다.
struct __kfifo {
unsigned int in;
unsigned int out;
unsigned int mask;
unsigned int esize;
void *data;
};
복수 생산자와 복수 소비자를 상정한 bounded 큐도 있다. 링이라는 이름답게 네트워크 쪽에서 주로 쓰고 BPF 모듈에서 CPU 맵을 구현하는 데에도 쓴다.
struct ptr_ring {
int producer ____cacheline_aligned_in_smp;
spinlock_t producer_lock;
int consumer_head ____cacheline_aligned_in_smp; /* next valid entry */
int consumer_tail; /* next entry to invalidate */
spinlock_t consumer_lock;
/* Shared consumer/producer data */
/* Read-only by both the producer and the consumer */
int size ____cacheline_aligned_in_smp; /* max entries in queue */
int batch; /* number of entries to consume in a batch */
void **queue;
};
잡다한 것들
list_lru라는 것도 있다. 캐시 동작 정책 얘기할 때 나오는 그 LRU인데, 쓰는 곳을 보면 역시나 그렇다.
struct super_block {
...
struct list_lru s_dentry_lru ____cacheline_aligned_in_smp;
struct list_lru s_inode_lru ____cacheline_aligned_in_smp;
...
};
BPF 모듈에도 bpf_lru라는 게 있다. LRU 맵 구현을 위한 것이다.
plist는 우선순위가 있는 객체(가령 태스크)들을 효율적으로 다루기 위한 것이다. 스케줄링과 스왑 쪽에서 쓴다.
scatterlist는 이름처럼 scatter-gather I/O를 위한 데이터 조각을 담은 메모리 페이지들의 리스트다. 네트워크와 파일 시스템 쪽에서 두루 사용한다.
quicklist는 메모리 페이지 테이블에 사용하는 메모리 페이지들을 재사용하기 위한 (흐흐흐…) 리스트다. 패치셋 설명 참고.
list_sort는 이름처럼 정렬 함수를 제공하는 모듈이다. 리스트인 만치 합병 정렬이다.
보자, 이제 리스트란 리스트는 모두 훑은 건가… 했더니,
RCU 버전
동시 접근 제어에 RCU를 쓸 때는 리스트 조작 방식이 미세하게 다르다. 가령 노드를 리스트에서 제거할 때 next 포인터를 (일부러 유효하지 않은 값으로 오염시키지 않고) 그대로 남겨둔다면 reader 쪽에서 계속 순회가 가능하게 된다. (역방향 순회는? 포기한다.) 둘을 비교해 보자.
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
WRITE_ONCE(prev->next, next);
}
static inline void __list_del_entry(struct list_head *entry)
{
if (!__list_del_entry_valid(entry))
return;
__list_del(entry->prev, entry->next);
}
static inline void list_del(struct list_head *entry)
{
__list_del_entry(entry);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
static inline void list_del_rcu(struct list_head *entry)
{
__list_del_entry(entry);
entry->prev = LIST_POISON2;
}
hlist, hlist_nulls에도 각기 대응하는 RCU 버전이 있다.
마지막으로 rcu_cblist가 있는데, RCU 구현 자체에서 쓰는 콜백 리스트다.
