재미없는 성능 개선 사례 - Redis
icache가 성능에 끼치는 영향을 확인해 보려고 처음 만지작거린 건 Redis였다. 인기 좋은 서버형 인메모리 NoSQL DB인데 Memcached 대용으로도 많이 쓰인다고 한다. key-value 구조를 기반으로 해서 비트맵, 리스트, 셋, 해시 테이블 등으로 지원 타입을 확장했으며 클러스터링, 프로시저, 메시지 브로커 등의 부가 기능까지 나름의 방식으로 제공한다. 즉, ‘full-featured’ NoSQL DBMS를 지향하는 프로젝트이다.
icache 미스가 줄도록 Redis를 바꾸는 걸 포기한 이유는 두 가지이다. 프로파일링을 해 보니 전형적 요청(GET, SET, …)을 하나 처리하는 데 실행하는 인스트럭션 수가 10k개(이전 포스트의 “어림셈” 참고)가 안 됐다. 그러니 실행 구간을 나눠 봐야 캐시 적중률을 높일 여지가 많지 않다. 또 다른 이유는 여타 오버헤드가 많다는 점이었다. 캐시 활용률 개선은 보통 성능 개선 여정의 막바지에 이뤄지는 일이다. 엔지니어링 관점에서 Redis에게는 걸을 수 있는 길이 많이 남아 있다.
이 글에선 Redis에서 성능 개선이 가능한 부분들을 살펴본다.
가능성 타진
낯선 길에 발을 들이기 전에는 언덕에라도 올라 길이 어떻게 뻗어 있는지 가늠해 볼 일이다.
라이브러리 형태 DB인 SQLite에서 간단한 SELECT 한 번에도 인스트럭션 20k개가 필요했는데 Redis에서 요청 한 개를 10k개도 안 되는 인스트럭션으로 처리하는 건 일견 신기해 보인다. 하지만 SQLite에서 SQL 문 파싱에 인스트럭션 절반을 소모한 데 반해 Redis에서는 단순한 명령 문법과 프로토콜 덕분에 파싱이 쉽다. 그리고 Redis나 Memcached의 핵심은 거칠게 말해서 hsearch() 함수에 통신 인터페이스를 붙인 것이다. 빠른 게 당연하다.
이런 단순한 네트워크 기반 응용에서는 응용 자체보다 통신에 더 많은 CPU를 쓰는 경우가 종종 있다. Redis의 기본 동작에는 파일 I/O가 수반되지 않으니 (RDB와 AOF는 논의에서 제외) 대략적으로 커널 공간 동작이 곧 네트워킹 동작이라고 보면 된다. 한편 perf 명령에서는 이벤트 이름에 “:k”나 “:u” 같은 수식자를 붙여서 특정 공간에서의 카운트를 얻을 수 있다.
다음은 Redis 패키지에 포함된 redis-benchmark 프로그램으로 이 요청 저 요청 섞어 보내서 잰 redis-server 프로세스의 실행 인스트럭션 수이다. “instructions”는 총 실행 인스트럭션 수, “instructions:u”는 사용자 공간에서 실행한 인스트럭션 수이다. 루프백을 통한 TCP 통신(comb-tcp-orig)과 유닉스 도메인 소켓을 통한 통신(comb-unix-orig)에 대해 측정했다. (5회 수행 평균. 편차 2% 이내.)
| 테스트 케이스 | instructions (A) | instructions:u (U) | 비율 (U/A) |
|---|---|---|---|
| comb-tcp-orig | 268662337470 | 87467059937 | 32.56 % |
| comb-unix-orig | 144270565158 | 87056703672 | 60.34 % |
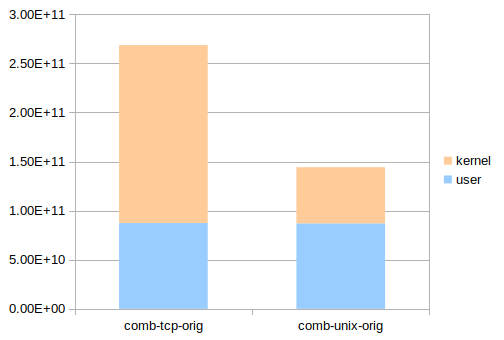
TCP에서는 응용 자체보다 통신에 2배나 많은 인스트럭션을 쓴다. 그나마 사정이 나은 유닉스 도메인 소켓에서도 40%가 통신 비용이다. 이래선 애써 응용을 최적화 해도 표가 안 난다. 가령 (가능할 리 없지만) 응용의 실행 인스트럭션 수를 절반으로 줄여도 TCP 사용 시 전체적으로는 16% 감소일 뿐이다. 파이프라이닝이나 다중 동작 명령을 통해 통신 비용 비율을 낮출 수도 있겠지만 항상 가능한 해법은 아니다. 응용의 외부에 해당하는 통신 메커니즘을 그대로 유지한다고 하면 결국 33%와 60%라는 값이 궁극적 한계가 된다. 통신 메커니즘을 그대로 유지한다고 하면, 말이다.
통신 비용 줄이기
제작 의도 대로라면 Redis는 일반적으로 시스템의 유일한 주요 서버로 동작하게 된다. (반면 캐시로서의 정체성이 명확한 Memcached는 다른 서버와 함께 도는 경우가 많다.) 그렇다면 DPDK 같은 사용자 공간 네트워킹을 생각해 볼 수 있다. Redis를 향하는 게 아닌 패킷은 KNI를 통해 운영체제에게 전달하면 된다.
이미 Seastar Project에서 Memcached를 가지고 시도를 해 봤다. 당연히 성능이 상당히 향상된다. 그리고 Redis와 호환되면서 높은 성능을 추구하는 Pedis란 것도 있다. 불가사리의 TCP/IP 스택을 사용하면 마찬가지로 성능이 향상된다. 그리고 ANS라는 스택을 사용하도록 변형된 Redis도 있다.
만약 전송 프로토콜로 UDP를 사용할 수 있다면 Seastar나 ANS까지 필요 없이 간단한 코드만으로 DPDK와 응용 프로그램을 이어 붙일 수 있다. 아쉽게도 Redis 프로토콜은 TCP를 전제한다. 반면 Memcached 프로토콜은 UDP도 지원한다.
통신과 관련해 Redis에는 작은 개선 가능성이 하나 더 있다. 설계 목표 중 하나가 “사람이 읽을 수 있을 것”이기에 Redis 프로토콜은 텍스트 기반이다. 그런데 사람이 쉽게 읽을 수 있는 건 머신에게 읽기 불편한 (변환이 필요한) 것이고, 프로토콜의 주된 사용자는 결국 머신이다. 사람을 위한 단순 프로토콜이 따로 있으니 기본 프로토콜은 머신에게 맞추는 게 어땠을까 싶다. 반면 Memcached에는 바이너리 프로토콜이 추가됐다. 보통은 프로토콜 형식이 성능에 별 영향을 주지 않지만 요청당 실행 인스트럭션 수가 적은 응용에서는 그마저도 차이를 만든다.
여담으로, Memcached처럼 클라이언트와 서버가 같은 호스트에서 동작할 가능성이 꽤 있는 경우에는 공유 메모리를 기반으로 좀 더 효율적인 통신 메커니즘을 고안하는 것도 고민해 볼 만하다. 근데 그렇게까지 할 거면 아예 데이터를 공유 메모리에 저장하고 클라이언트 코드에서 그 데이터를 직접 조작하는 게 나을 수도 있다. 네트워크 서버가 필요하면 그 클라이언트 코드로 만들면 된다.
실행 인스트럭션 줄이기
통신 비용을 제하고 나면 남는 건 자잘한 칼질거리들이다. 각각은 1~5% 정도의 쪼잔한 효과가 있을 뿐이지만 그것도 여럿 모으면 덩어리가 좀 된다. 한편으로 프로그램이 날씬해질수록 칼질의 상대적 효과가 더 커진다. 그래서 인스트럭션 줄이기 작업은 은근히 중독성이 있다.
(참고: 설명에 등장하는 실험용 저장소의 커밋들은 성능 향상 효과 확인만을 위한 것이다. 충분한 검토가 이뤄지지 않았으며 프로그램 전체로 완전하게 적용되지도 않았다.)
메모리 할당 줄이기
Redis는 동적 메모리 할당을 많이 하는 편이다. 그래서 메모리 할당을 줄이기 위한 자잘한 최적화 로직도 좀 있고, jemalloc을 가져다 사용하며, 심지어 런타임 메모리 단편화 제거 기능을 제공한다! (단편화 제거라는 이름은 거창한데 핵심은 새로 할당한 메모리 공간으로 데이터를 옮기고 이전 공간을 해제하는 것이다. 메모리 덩어리의 단편화 정도를 확인해서 동작 수행 여부를 판단하는 게 흥미로운 부분이다.)
키-값 저장소니까 키와 값을 저장할 공간을 할당하는 건 어쩔 수 없다. 하지만 다른 할당은 최대한 줄여야 한다. 가령 자료구조론 교과서에 나옴직한 연결 리스트 구현(adlist.h, adlist.c)보다는 리눅스 커널 방식 구현(설명과 간략 버전)이 일반적으로 더 낫다. 노드를 위한 별도 메모리 할당도 없고 조작 루틴에 if도 없다. 객체의 연결 차수가 한정적이어야 한다는 제약이 있기는 한데 안 그런 경우 찾기가 쉽지 않다. 변경 작업도 간단하다.
Redis의 핵심 자료 구조인 연관 배열 구현(dict.h, dict.c)에도 마찬가지 이슈가 있다. 게다가 다양한 자료 구조 지원을 위한 robj(struct redisObject) 타입까지 있다 보니 키-값 쌍 하나 저장하는 데 메모리 공간을 4개 할당해야 한다.
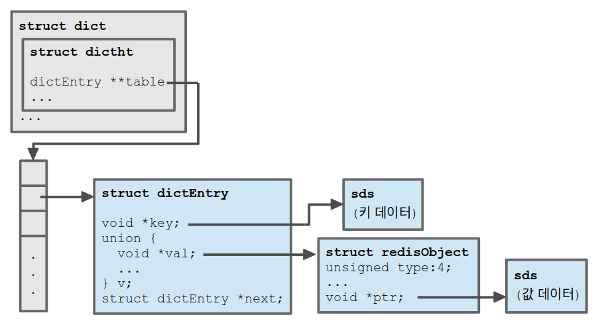
몇 가지 예외가 있기는 하지만 Redis에서 이진 문자열 키와 값은 기본적으로 immutable 데이터이다. 그렇다면 새 타입을 도입하거나 기존 타입들을 공용체로 병합해서 객체 구조를 단순화 할 수 있다. 한편 현재 Redis에서도 값이 짧은 경우에는 embedded string object라는 이름으로 robj와 sds를 이어 붙여서 할당한다.
데이터 저장 방식과 관련해 또 다른 개선 가능성이 있다. Redis에서 어떤 이진 문자열 데이터를 받거나 보낼 때는 프로토콜에 따라 길이가 들어간 접두부(*LENGTH\r\n)와 접미부(\r\n)가 앞뒤로 붙는다. 그래서 데이터를 보낼 때마다 접두부를 생성해서 세 조각(접두부, 데이터, 접미부)을 차례로 보낸다. 그렇다면 데이터를 저장할 때 접두부와 접미부까지 포함시킬 수도 있을 것이다. 그러면 데이터 입출력 (특히 출력) 로직이 단순해지면서 또 다른 최적화 가능성까지 생긴다. 물론 약간의 메모리 오버헤드가 생기겠지만 작은 데이터를 많이 저장하는 경우가 아니면 무시할 만하다.
동적 메모리 할당 오버헤드를 줄이는 전통적인 해법으로 객체 풀링도 있다. Redis의 요청 처리 로직을 따라가 보면 요청을 처리할 때마다 자잘한 메모리 공간 여러 개를 할당했다가 다시 해제하는 걸 볼 수 있다. 할당과 해제가 빈번한 메모리 공간을 이런저런 방식으로 재사용할 수 있다.
실행 인스트럭션을 줄인다는 맥락과는 맞지 않지만 메모리 할당 횟수 대신 크기를 줄이는 방법도 있다. 인메모리 데이터 저장소라고 해도 모든 데이터에 활발한 접근이 이뤄지는 건 아니다. 그렇다면 잘 쓰이지 않는 데이터를 LZ4 등으로 압축해서 저장했다가 접근 때 풀어서 쓸 수 있다. 커널에서도 압축 램디스크나 압축 스왑 캐시 형태로 메모리 데이터를 압축하는 시대니 말이다. 사실 Redis에는 이를 위한 요소들이 이미 준비돼 있다. 백업 파일(RDB)에서 데이터를 LZ4로 압축해서 저장하고 있고, 데이터 만료 기능을 위해 객체별로 접근 시간을 관리하고 있으며, 데이터를 순회하며 어떤 동작을 수행하는 기능(단편화 제거)이 이미 구현돼 있다.
중복 동작 제거
프로파일링과 약간의 코드 추적을 해 보면 Redis에서 SET 요청 하나를 처리하는 동안 검색 연산을 많이 수행하는 걸 볼 수 있다. 메인 테이블(server.db[i].dict)에서 같은 키로 적어도 2번, 많으면 4번까지 수행한다. 특별한 이유가 있는 건 아니고 덜 유연한 인터페이스 설계의 결과이거나 구현 상의 게으름 때문이다. 이런저런 방식으로 중복 동작을 줄일 수 있다. 다른 요청들에도 비슷한 이슈가 있다.
응답을 보내는 과정에도 중복 동작이 있다. 응답마다 한 번씩 호출해야 할 함수를 응답 내 각 토큰마다 호출한다. 호출 구조를 조정해서 중복 동작을 없앨 수 있다.
프로토콜 파싱
수신 메시지를 파싱하는 루틴을 살짝 정리하는 걸로도 성능이 좀 개선된다. 미세한 개선이지만 실행이 잦은 함수인 데다가 요청당 인스트럭션 수가 적다 보니 표가 좀 난다.
함수 호출 줄이기
Redis는 하는 일에 비해 함수 호출이 많은 편이다. 그러다 보니 함수 호출 자체의 비용도 성능에 영향을 준다. 들어갔다 바로 나오는 경우가 많은 함수의 실제 호출을 늦추고 자주 호출되는 단순 함수들을 인라인으로 만들어서 함수 호출 비용을 줄일 수 있다.
주섬주섬
자잘한 손질 몇 가지를 모으니 사용자 공간 인스트럭션 수 기준으로 20% 정도 차이가 난다.
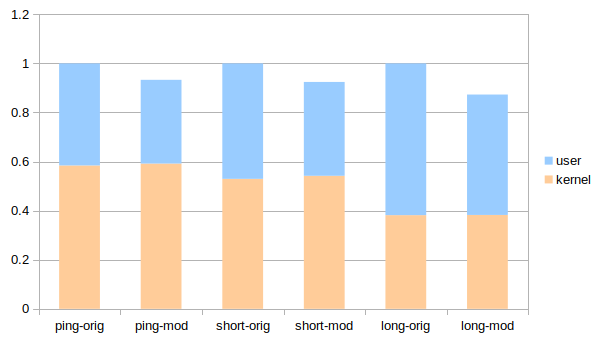
유닉스 도메인 소켓 기준이고 원본 버전을 기준으로 정규화 한 것이다. 각 케이스는 다음과 같다.
- ping: PING 요청과 PONG 응답을 주고 받음. 기초대사량.
- short: 짧은 데이터로 GET과 SET 요청 수행. 평범한 캐시 용도.
- long: 10kB 데이터로 GET과 SET, 그리고 (10개 데이터) MSET 요청 수행. 진지한 사용.
언급한 다른 가능성들까지 구현한다면 아마 30% 정도까지 갈 수 있을 것이다. 하지만 그래봐야 통신 비용을 합치면 유닉스 소켓 사용 시 18%에 TCP 사용 시 10%다. 역시 신경 쓸 곳은 여기가 아니다.
링크 타임 최적화
함수 호출 줄이기를 하다가 문득 생각이 나서 LTO를 해 봤다. 잘하면 공짜로 몇 퍼센트를 줄일 수 있을지 모른다.
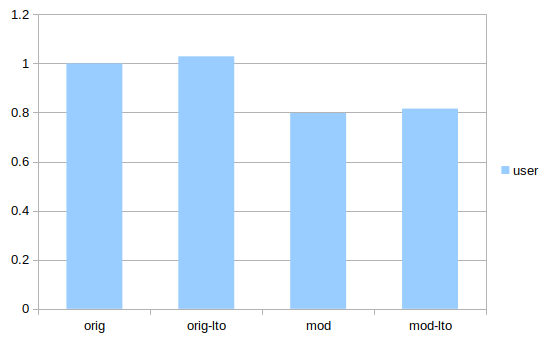
근데 두 버전 모두에서 실행 인스트럭션 수가 되려 2~3% 증가했다 (GCC 7.2 사용). 캐시 등의 다른 영향까지 포함한 실제 성능이 어떨지는 모를 일이다. 하지만 LTO가 모든 프로그램에서 확인 없이 믿고 쓸 수 있는 건 아닌 모양이다.
