VPP - 그래프
이전 포스트 말미에서 언급한 VPP에서는 패킷 처리 과정을 유향(directed) 그래프로 표현한다. 뭐 특별한 게 있는 건 아니고 여러 절차와 분기로 이뤄진 패킷 처리 과정을 쪼개놓은 것이다. 사실 전통적인 네트워크 스택도 그래프로 표현 가능하다. 이것저것 다 생략해서 그려보자면,
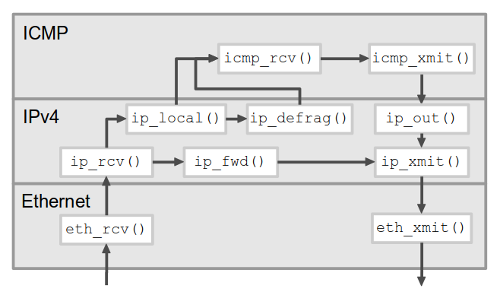
노드가 몇십 개를 잘 넘지 않고 간선도 별로 없는 희소 그래프다. 즉, VPP에서 그래프 개념을 쓰는 건 신장 트리를 찾거나 판매 사원을 여행시키기 위해서가 아니다. VPP를 이용해 새로운 네트워크 기능을 구현한다는 건 일반적으로 새 노드를 만들어서 기존 그래프에 연결하는 것이다.
전통적 구현에서 그래프의 간선은 함수 호출이다. 다음 노드에 해당하는 함수를 꼬리 호출(tail call)하는 게 보통이다. VPP에서는 그래프 간선을 다른 형태로 구현하는데, 그게 이 글의 주제다.
두 가지 실행 순서
상당히 복잡한 네트워크 기능을 하나 생각해 보자. 한 인터페이스로 패킷을 수신하고, 어떤 계산을 통해 출력 인터페이스를 결정하고, 그 인터페이스로 패킷을 출력한다.

각 노드에서 실행하는 인스트럭션 수를 세어 보니 몇천 개 수준인데 대략 1:2:1이었다고 하자. 이제 이 기능이 수신 큐에 있는 패킷 3개를 처리해야 한다.
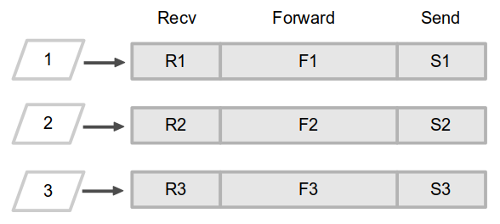
어떤 순서로 실행하는 게 더 효율적일까?
- 패킷 우선: R1 - F1 - S1 - R2 - F2 - S2 - R3 - F3 - S3
- 작업 우선: R1 - R2 - R3 - F1 - F2 - F3 - S1 - S2 - S3
실행하는 인스트럭션 수에는 차이가 없지만 캐시 적중률은 다를 수 있다. 캐시를 두고 경쟁하는 세 가지 데이터를 생각해 보면,
-
패킷 데이터
수신 패킷을 저장한 버퍼와 메타 데이터. 상당수 응용에서는 패킷 데이터 앞쪽 수십 바이트에만 접근한다. 점보그램까지 가면 모를까 커 봐야 2kB가 안 된다.
패킷 우선 순서가 각 패킷 데이터에 더 짧게 접근하므로 캐시에 부담을 덜 준다. 패킷 데이터가 캐시에서 얼른 빠지면 그 라인을 다른 데이터가 차지할 수 있고, 경쟁 수준이 낮아지면 캐시 적중률이 높아질 가능성이 생긴다. 근데 데이터가 워낙 작아서 별 표시가 안 난다.
-
정적 데이터
각 노드에서 접근하는 데이터. Forward 노드에서 참조하는 포워딩 테이블 같은 데이터이며 꽤 클 수도 있다. 실제 접근하는 데이터 세트가 패킷마다 전혀 다를 수도 있고 완전히 같을 수도 있다.
작업 우선 순서가 각 정적 데이터에 더 짧게 접근하므로 캐시에 부담을 덜 준다.
-
프로그램 코드
노드 종류에 따라 수십 바이트에서 수백 킬로바이트까지 다양하다.
R-F-S 코드 전체가 L1 icache에 들어가는 장난감 프로그램에서는 두 순서에 차이가 없다. 하지만 그 외 경우에선 작업 위주 순서가 캐시에 부담을 덜 준다. 그리고 어떤 노드의 실행 코드가 icache에 다 들어간다면 작업 우선 순서에서 인스트럭션 페치 측면의 최고 성능을 기대할 수 있다.
그래서 일반적으로 작업 우선 순서에서 캐시 적중률이 높다고 예상할 수 있다. 실행 인스트럭션 수는 같은데 캐시 적중률이 높으니 소모 사이클이 줄어서 스루풋이 높아진다. VPP 소개 페이지에 좋은 비유가 있는데, 나무 조각 여러 개를 톱질하고 사포질해서 구멍을 내야 할 때 한 조각씩 작업하기보다는 모든 조각들을 한번에 자르고, 한번에 다듬고, 한번에 뚫는 게 효율적이다.
동일 작업 반복으로 효율을 높인다는 개념을 극단으로 밀고가면, 다중 프로세서 시스템의 각 코어가 한 가지 동작만 수행하게 할 수 있다. 작업 노드마다 메시지 큐가 있고 각 코어에 고정된 작업 스레드는 큐에서 꺼낸 메시지를 처리하고 다음 노드의 메시지 큐에 집어넣는 동작을 반복한다. 즉 파이프라인 구조다. 균일한 작업 분산을 위해 위 예의 Forward 작업에는 작업 스레드를 두 배로 할당해 줘야 할 것이다. 마침 시스템에 코어가 4개 있어서 (그리고 SMP여서) 각 코어가 작업 스레드 하나씩을 맡아서 실행한다고 하자.
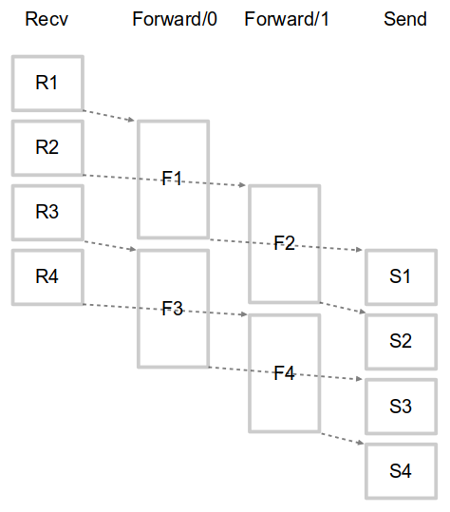
각 코어가 한 가지 작업만 반복하니 캐시 적중률이 극대화된다. 패킷 몇 개만 보면 다른 실행 구조(각 코어가 패킷 우선 순서 반복하기)에 비해 추가 지연이 있을 수 있지만 캐시 적중률 상승에 의해 금방 상쇄될 것이다. 최고의 스루풋을 내 줄 이 동작 구조에는 사소한 결점이 하나 있는데, 전제들이 현실적이지 않다는 것이다. 작업 크기가 위와 같이 정수 비로 떨어질 리도 없고, 입력 트래픽과 무관하게 작업 크기가 일정한 경우도 드물다. 최적화된 컨베이어 벨트는 아름답게 동작하지만 절대 유연하지 않다.
유연성이라는 전제 하에 효율성을 최대화 하는 방법은 각 노드를 가급적 많은 패킷들로 실행하는 것이다. 이렇게 모아서 처리하면 일부 패킷은 처리 완료 시점이 늦춰진다. 즉 지연이 발생한다. 첫 패킷은 무조건 원래보다 늦어지지만 마지막 패킷은 소모 사이클 감소 효과 때문에 당겨진다. 각 패킷이 겪는 실제 지연은 캐시 적중률 개선 효과와 노드 길이 등에 따라 달라진다.
VPP의 구현
각 노드는 패킷 벡터를 받아서 노드별 처리를 수행한 후 패킷별 다음 노드를 결정한다. 패킷 벡터 인자를 받지 않는 입력 노드는 패킷의 원천이고 다음 노드를 결정하지 않는 출력 노드는 패킷의 싱크이다. 한 노드의 처리가 끝나면 간선을 거쳐 다음 노드(들)로 이동한다.
“다음 노드로 이동”을 구현하는 두 가지 방식이 있다. 각 노드에서 다음 노드에 해당하는 함수를 직접 호출할 수도 있고, 현재 노드를 빠져 나온 다음에 다음 노드 함수를 호출할 수도 있다. 전자는 스택 기반 깊이 우선이고 후자는 큐 기반 너비 우선이다. 인스트럭션 개수 측면에서는 별 차이가 없겠지만 오르내리기를 반복하는 높은 호출 스택은 캐시에 부담을 준다. 그리고 그래프가 단순하기에 너비 우선 방식에서 큐가 그리 길어지지 않는다. 너비 우선 방식을 채택한 VPP에서는 드라이버 코드가 노드 함수 호출을 반복한다.
(호출 스택을 쌓지 않는 동작 구조에는 단점이 하나 있다. 디버거로 스택 트레이스를 찍어도 패킷의 이전 처리 경로가 나오지 않는다. 사용자 공간 데이터 플레인 구현에 기대하는 것 중 하나가 편리한 디버깅인 걸 생각해 보면 아이러니하다. 많은 트레이드오프 지점에서 VPP는 일관성 있게 효율성을 택한다.)
그러면 각 노드의 함수는 다음과 같은 형태일 것이다.
void node_func(context_t ctx, arg_list_t args)
{
foreach_arg(args) {
/* 각 패킷(arg)을 적당히 처리... */
next_node_id = determine_next_node(arg);
next_node = ctx->find_or_enqueue(ctx->next_nodes, next_node_id);
next_node->args->append(arg);
}
}
그리고 드라이버는 대략 다음과 같은 형태일 것이다.
void driver_loop(context_t ctx) {
while (1) {
// 패킷을 받아오는 입력 노드를 먼저 호출
foreach_node(ctx->input_nodes)
node->func(ctx, NULL);
// 패킷이 싱크로 사라질 때까지 중간 노드와 출력 노드를 호출
while (!is_empty(ctx->next_nodes)) {
next_node = dequeue(ctx->next_nodes);
node = node_by_id(ctx, next_node->id);
node->func(ctx, next_node->args);
}
}
}
전역 설정 및 상태 변수 모음인 context_t에 해당하는 것이 VPP의 vlib_main_t와 vlib_node_runtime_t이고, arg_list_t에 해당하는 것이 vlib_frame_t(스택 프레임에서 유래한 이름)이다. 패킷들을 미리 할당해서 풀을 만들어 두고 그 풀 내의 인덱스 번호를 인자로 사용한다.
그래서 node_func()는 대략 다음 코드에 대응한다.
static uword
some_node_func (vlib_main_t *vm, vlib_node_runtime_t *node, vlib_frame_t *frame)
{
u32 n_left_from, *from, next_index, *to_next, n_left_to_next;
from = vlib_frame_vector_args (frame); // 받은 인자 배열 얻기
n_left_from = frame->n_vectors; // 남은 인자 수
next_index = node->cached_next_index; // 최근 처리 패킷의 '다음 노드'. 보통
// 다음 노드가 잘 바뀌지 않으므로 캐싱.
while (n_left_from > 0)
{
// 다음 노드에게 줄 인자 목록 준비
vlib_get_next_frame (vm, node, next_index, to_next, n_left_to_next);
while (n_left_from > 0 && n_left_to_next > 0)
{
u32 bi0;
vlib_buffer_t *b0;
u32 next0;
// 일단 현재 추측(next_index)에 따라 다음 노드 인자 목록에 인자 저장.
// 곧 결정하는 다음 노드(next0)가 혹시라도 next_index와 다르면 그때 정정.
bi0 = from[0];
to_next[0] = bi0;
from += 1;
to_next += 1;
n_left_from -= 1;
n_left_to_next -= 1;
// vlib_buffer_t는 `struct sk_buff`나 `struct mbuf`에 해당
b0 = vlib_get_buffer (vm, bi0);
// 이런저런 노드별 처리를 하고...
next0 = determine_next_node (b0); // 노드별 로직에 따라 다음 노드 결정
// next0와 next_index가 같으면: 아무것도 하지 않음.
// 다르면:
// 방금 추가한 인자를 제외하고 vlib_put_next_frame() 하고,
// next_index = next0;
// next_index로 vlib_get_next_frame() 하고,
// 새 인자 목록에 bi0 추가.
vlib_validate_buffer_enqueue_x1 (vm, node, next_index,
to_next, n_left_to_next,
bi0, next0);
}
// 다음 노드 인자 목록 저장
vlib_put_next_frame (vm, node, next_index, n_left_to_next);
}
return frame->n_vectors;
}
VLIB_REGISTER_NODE (some_node) = {
.function = some_node_func,
.name = "some-node",
...
.n_next_nodes = SOME_NODE_N_NEXT,
.next_nodes = {
[SOME_NODE_NEXT_DROP] = "error-drop",
[SOME_NODE_NEXT_PUNT] = "error-punt",
[SOME_NODE_NEXT_FILTER] = "filter",
...
},
...
};
안쪽 루프의 변수 이름에 0이 붙어 있는 게 눈에 띈다. vpp/src/vnet의 어떤 노드에는 1, 2, 3도 있다.
static uword
another_node_func (...)
{
...
while (n_left_from > 0)
{
vlib_get_next_frame (...);
while (n_left_from >= 4 && n_left_to_next >= 4)
{
u32 bi0, bi1, bi2, bi3;
vlib_buffer_t *b0, *b1, *b2, *b3;
u32 next0, next1, next2, next3;
to_next[0] = bi0 = from[0];
to_next[1] = bi1 = from[1];
to_next[2] = bi2 = from[2];
to_next[3] = bi3 = from[3];
from += 4;
to_next += 4;
n_left_from -= 4;
n_left_to_next -= 4;
...
vlib_validate_buffer_enqueue_x4 (vm, node, next_index,
to_next, n_left_to_next,
bi0, bi1, bi2, bi3,
next0, next1, next2, next3);
}
while (n_left_from >= 0 && n_left_to_next >= 0)
{
...
}
vlib_put_next_frame (...);
}
}
즉 루프 풀어쓰기(unrolling)다. 사소하지만 인스트럭션이 좀 줄어들기도 하고, 컴파일러가 SIMD 인스트럭션을 사용해 최적화 할 여지가 생기고, 노드별 처리 루틴의 시간 지역성을 더 높여서 인스트럭션 캐시 미스 가능성을 더욱 줄인다. 풀어 쓴 루틴으로 성능 측정을 돌려 보고 살짝 올라간 스루풋에 미소 짓는 개발자의 모습이 보인다. 효율성을 위해서든 뭐를 위해서든 이 정도 집착은 존경해 줘야 한다.
그리고 드라이버 루틴인 driver_loop()는 다음 코드에 대응한다.
vpp/src/vlib/main.c:
static_always_inline void
vlib_main_or_worker_loop (vlib_main_t * vm, int is_main)
{
vlib_node_main_t *nm = &vm->node_main;
vlib_thread_main_t *tm = vlib_get_thread_main ();
u64 cpu_time_now;
vlib_frame_queue_main_t *fqm;
...
...
/* Start all processes. */
if (is_main)
{
uword i;
nm->current_process_index = ~0;
for (i = 0; i < vec_len (nm->processes); i++)
cpu_time_now = dispatch_process (vm, nm->processes[i], /* frame */ 0,
cpu_time_now);
}
while (1)
{
vlib_node_runtime_t *n;
...
/* Next process input nodes. */
vec_foreach (n, nm->nodes_by_type[VLIB_NODE_TYPE_INPUT])
cpu_time_now = dispatch_node (vm, n,
VLIB_NODE_TYPE_INPUT,
VLIB_NODE_STATE_POLLING,
/* frame */ 0,
cpu_time_now);
...
/* Input nodes may have added work to the pending vector.
Process pending vector until there is nothing left.
All pending vectors will be processed from input -> output. */
for (i = 0; i < _vec_len (nm->pending_frames); i++)
cpu_time_now = dispatch_pending_node (vm, i, cpu_time_now);
/* Reset pending vector for next iteration. */
_vec_len (nm->pending_frames) = 0;
...
}
}
static_always_inline u64
dispatch_node (vlib_main_t * vm,
vlib_node_runtime_t * node,
vlib_node_type_t type,
vlib_node_state_t dispatch_state,
vlib_frame_t * frame, u64 last_time_stamp)
{
uword n, v;
...
n = node->function (vm, node, frame);
...
}
static u64
dispatch_pending_node (vlib_main_t * vm, uword pending_frame_index,
u64 last_time_stamp)
{
vlib_node_main_t *nm = &vm->node_main;
vlib_frame_t *f;
vlib_next_frame_t *nf, nf_dummy;
...
p = nm->pending_frames + pending_frame_index;
n = vec_elt_at_index (nm->nodes_by_type[VLIB_NODE_TYPE_INTERNAL],
p->node_runtime_index);
f = vlib_get_frame (vm, p->frame_index);
...
last_time_stamp = dispatch_node (vm, n,
VLIB_NODE_TYPE_INTERNAL,
VLIB_NODE_STATE_POLLING,
f, last_time_stamp);
...
}
pending_frames가 다음 처리 작업(노드 + 인자들)의 목록이다. VLIB_NODE_TYPE_INTERNAL은 중간 노드뿐 아니라 장치로 출력하는 노드도 포함한다.
위의 vlib_main_or_worker_loop()를 보면 주 스레드에서 루프 전에 dispatch_process()라는 함수를 호출하는 게 보인다. 네트워크 응용에는 패킷 처리 루틴만 필요한 게 아니라 지속적으로 동작하는 루틴도 필요하다. 예를 들어 인터페이스 링크 상태를 확인하는 HA 기능이 있을 수 있다. 그런 기능을 분리된 프로세스로 구현하면 busy waiting 하는 VPP 응용 때문에 CPU를 충분히 할당받지 못할 수도 있고, 무엇보다 프로세스간 문맥 전환이 (오버헤드!) 발생한다. 그래서 최고의 성능을 위해선 그런 기능들도 VPP 위에서 동작시키는 게 좋은데, 그때 VPP가 그 ‘프로세스’들을 스케줄링 하는 메커니즘이 다음 포스팅의 주제이다.
