VPP - 스케줄링
데이터 플레인의 주 실행 흐름은 패킷 수신에서 시작된다. 하지만 그와 독립적인 간헐적 실행 흐름이 있을 수 있다. 예를 들어 인터페이스 링크 상태 변화를 감지해서 그에 따라 패킷 처리 경로를 바꾸는 로직이 있을 수 있고, 패킷 재전송이나 대기 중단 같은 타이머 기반 동작이 있을 수도 있다.
CPU를 충분히 많이 소모하는 기능이라면 코어를 따로 할당해 줄 수도 있을 것이다. 가령 라우터의 데이터 플레인과 컨트롤 플레인을 한 시스템에서 구현할 때는 일부 코어를 컨트롤 플레인에 할당하고 나머지를 데이터 플레인에서 사용하는 것도 가능하다. 하지만 많은 경우에서는 그러는 것이 코어 낭비이다. 그렇다고 데이터 플레인 프로세스와 기타 기능을 위한 프로세스가 서로 경쟁하며 서로 선점하게 하는 것도 좋지 않다. 스케줄링 정책 및 매개변수에 따라 한쪽 프로세스가 기아를 겪을 수도 있고, 데이터 플레인 동작에 예상할 수 없는 지연이 발생할 수도 있으며, 무엇보다 힘들게 없앤 문맥 전환 오버헤드를 다시 만나야 한다.
VPP가 제공하는 해법은 간헐적으로 짧게 실행되는 루틴들을 위한 비선점형 실행 구조이다. 간헐 실행 루틴들을 그 구조 위로 옮기면 성능 감소 가능성을 최소화 할 수 있다. VPP가 프로세스 스케줄링까지 하는 셈인데, 아예 운영체제가 되려는 건가 싶기도 하고 (사실 VPP는 베어메탈 상의 동작을 염두에 두고 만들어져 있다.) 여러 기능들이 한 프로그램으로 모이면 너무 복잡해지지 않을까 싶기도 하지만 동작 효율성을 놓고 보면 분명 최선의 방법이다.
그래서, VPP는 어떻게 간헐적으로 실행되는 루틴들을 스케줄링 할까?
타이머
이미 운영체제가 강력한 타이머 기능을 제공하지만 데이터 플레인 구현에 CLOCK_PROCESS_CPUTIME_ID 클럭까지는 필요치 않다. 네트워크 스택을 구현하는 데는 비교적 간단한 타이머로도 충분하다. 원하는 상대 시간 후에 원하는 인자로 원하는 콜백이 호출되게 할 수 있으면 된다. 그리고 해상도가 높을 필요가 없다. 마이크로초 수준이면 충분하다. 또 타임아웃 값에 어떤 패턴이 있고 응용별로 타임아웃 값의 범위가 정해져 있다. 그리고 타이머가 만료되는 경우가 드물다. 동일한 상대 시간 값으로 갱신을 반복하다 삭제되는 게 보통이며 째깍째각 만료까지 가는 건 통신 장애라도 발생하지 않는 한 보기 힘들다. 이렇게 기능 요구 수준이 약한 대신 타이머 조작 동작, 특히 활성 타이머를 갱신하는 동작을 효율적으로 수행할 수 있어야 한다.
만료 시점이 가까운 타이머부터 차례로 이어지는 연결 리스트 형태로 구현할 수 있을 것이다. 타이머 갱신은 삭제 동작 더하기 추가 동작으로 구현할 수 있다. 삭제 동작이 효율적이려면 이중 연결 리스트여야 한다. 추가 동작이 효율적이려면 특정 시각에 대응하는 위치에 바로 접근할 수 있어야 한다. 따라서 각 항목이 단위 시간(tick)에 대응하는 배열을 만들고, 각 배열 항목에 리스트를 달아 놓으면 된다. 시간은 돌고 도는 거니까 배열의 끝과 끝을 이어 붙이고 현재 시각을 나타내는 커서를 둘 수 있다. 그러면 초침만 달린 시계 모양이 나온다.
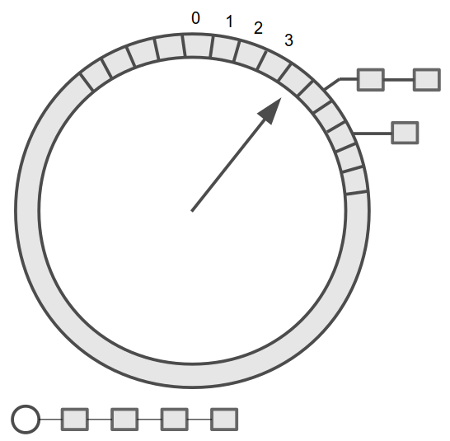
시간 해상도가 1초이고 슬롯 개수가 60개라면 진짜 벽시계와 같은 모양이 된다. 타이머의 만료 시각의 시/분이 현재 시각과 다르면 (가령 현재 시각이 0시 30분 30초인데 만료 시각이 0시 31분 10초이면) 별도의 오버플로우 리스트(그림 아래의 리스트)에 달아 둔다. 1분 동안 초침이 째깍째각 슬롯들을 훑어나가며 만나는 타이머들을 만료 처리한다. 초침이 한 바퀴를 완전히 돌아서 0으로 되돌아오면 오버플로우 리스트의 타이머들 중에 다음 1분 내에 만료될 것들을 찾아서 적절한 슬롯에 달아놓는다. 그리고 또 초침이 돌아간다.
오버플로우 리스트에 타이머가 많이 달리면 1분마다 수행하는 재배치에 많은 시간이 걸린다. 그럴 땐 분침만 달린 시계 바퀴를 추가로 만들면 된다. ‘초’ 바퀴에서 초침이 한 바퀴 돌 때마다 ‘분’ 바퀴의 현재 슬롯에 달린 타이머들을 초 바퀴로 재배치 하고서 분침을 한 칸 전진시킨다. 이걸로도 부족하다면 시 바퀴를 만들면 된다. 또 각 바퀴의 슬롯 수를 조정해서 타임아웃 시간 범위를 조정할 수도 있다. 그리고 높은 정밀도가 필요하면 초 바퀴의 한 슬롯이 나타내는 단위 시간을 작게 줄이면 된다.
타이머를 사용하는 곳마다 적절한 매개변수(바퀴 단계 수, 바퀴 내 슬롯 개수 등) 값이 다를 것이다. 런타임에 매개변수 값을 확인해서 그에 맞게 동작하는 범용 루틴을 작성할 수도 있겠지만 그건 VPP 스타일이 아니다. 대신 컴파일 타임에 준 매개변수에 맞춰 생성되는 코드를 사용한다. C++ 템플릿의 C 버전이다.
vpp/src/vnet/tcp/tcp_timer.h:
...
#include <vppinfra/tw_timer_16t_2w_512sl.h>
...
vpp/src/vppinfra/tw_timer_16t_2w_512sl.h:
...
#define TW_TIMER_WHEELS 2
#define TW_SLOTS_PER_RING 512
#define TW_RING_SHIFT 9
#define TW_RING_MASK (TW_SLOTS_PER_RING -1)
#define TW_TIMERS_PER_OBJECT 16
#define LOG2_TW_TIMERS_PER_OBJECT 4
#define TW_SUFFIX _16t_2w_512sl
#define TW_FAST_WHEEL_BITMAP 0
#define TW_TIMER_ALLOW_DUPLICATE_STOP 1
#include <vppinfra/tw_timer_template.h>
...
vpp/src/vppinfra/tw_timer_16t_2w_512sl.c:
...
#include "tw_timer_16t_2w_512sl.h"
#include "tw_timer_template.c"
...
vpp/src/vppinfra/tw_timer_template.h: 파일 보기
vpp/src/vppinfra/tw_timer_template.c: 파일 보기
C++ 템플릿에 <...>가 붙는 것처럼 tw(timing wheel) 타이머 코드에도 뭐가 좀 붙는다. 다음처럼 좀 번잡한 이름을 사용하거나,
void
tcp_initialize_timer_wheels (tcp_main_t * tm)
{
tw_timer_wheel_16t_2w_512sl_t *tw;
/* *INDENT-OFF* */
foreach_vlib_main (({
tw = &tm->timer_wheels[ii];
tw_timer_wheel_init_16t_2w_512sl (tw, tcp_expired_timers_dispatch,
100e-3 /* timer period 100ms */ , ~0);
tw->last_run_time = vlib_time_now (this_vlib_main);
}));
/* *INDENT-ON* */
}
다음처럼 좀 괴랄한 코드를 사용해야 한다. tw_timer_template.h에 정의된 TW() 및 TWT() 매크로는 코드 가독성 향상이라는 목적을 정확하게 배신하고 있는 듯하다.
int
vlib_main (vlib_main_t * volatile vm, unformat_input_t * input)
{
...
/* Create the process timing wheel */
TW (tw_timer_wheel_init) ((TWT (tw_timer_wheel) *) nm->timing_wheel,
0 /* no callback */ ,
10e-6 /* timer period 10us */ ,
~0 /* max expirations per call */ );
...
}
타이머 구조가 갖춰졌으니 이제 시간의 수레바퀴를 돌릴 동력이 필요하다. 가장 가까운 타임아웃 시간에 운영체제로부터 어떤 방식(시그널, 콜백 호출, 파일 읽기, …)으로 알림을 받아서 필요한 동작을 수행할 수도 있겠지만 그런 오버헤드와 플랫폼 의존성은 VPP의 방식이 아니다. 그렇다면 반복적으로 현재 시간을 확인해서 틱이 바뀔 때마다 어떤 타이머 루틴을 실행하는 방식이 남는다. 어느 가상 입력 노드가 그 역할을 맡는다.
vpp/src/vnet/session/session_node.c:
static uword
session_queue_node_fn (...)
{
...
f64 now = vlib_time_now (vm);
/*
* Update TCP time
*/
tcp_update_time (now, my_thread_index);
...
}
VLIB_REGISTER_NODE (session_queue_node) =
{
.function = session_queue_node_fn,
...
.type = VLIB_NODE_TYPE_INPUT,
...
};
vpp/src/vnet/tcp/tcp.h:
always_inline void
tcp_update_time (f64 now, u32 thread_index)
{
tcp_set_time_now (thread_index);
tw_timer_expire_timers_16t_2w_512sl (&tcp_main.timer_wheels[thread_index],
now);
tcp_flush_frames_to_output (thread_index);
}
그러면 tw_timer_expire_timers*() 함수에서 틱이 지났는지 확인하고, 지났으면 초침 이동과 그에 따르는 온갖 동작들을 수행한다.
타이머 동작을 위해선 현재 시간을 알 수 있어야 한다. 즉 위의 session_queue_node_fn()에 등장한 vlib_time_now() 함수가 타이머 동작의 기반이다. CLOCK_REALTIME까지 필요한 건 아니고 CLOCK_MONOTONIC이면 되는데, 간단하게는 gettimeofday()나 timer_gettime()으로 구현할 수 있을 것이다. 표준 함수인 데다가 여러 아키텍처에서 VDSO 오브젝트에 포함돼 있으니 꽤 효율적이다. 하지만 VPP 개발자에게는 만족스럽지 않았다.
vpp/src/vlib/main.h:
always_inline f64
vlib_time_now (vlib_main_t * vm)
{
return clib_time_now (&vm->clib_time);
}
vpp/src/vppinfra/time.h:
always_inline f64
clib_time_now (clib_time_t * c)
{
return clib_time_now_internal (c, clib_cpu_time_now ());
}
always_inline f64
clib_time_now_internal (clib_time_t * c, u64 n)
{
u64 l = c->last_cpu_time;
u64 t = c->total_cpu_time;
t += n - l;
c->total_cpu_time = t;
c->last_cpu_time = n;
if (PREDICT_FALSE
((c->last_cpu_time -
c->last_verify_cpu_time) >> c->log2_clocks_per_frequency_verify))
clib_time_verify_frequency (c);
return t * c->seconds_per_clock;
}
/* Return CPU time stamp as 64bit number. */
#if defined(__x86_64__) || defined(i386)
always_inline u64
clib_cpu_time_now (void)
{
u32 a, d;
asm volatile ("rdtsc":"=a" (a), "=d" (d));
return (u64) a + ((u64) d << (u64) 32);
}
#elif ...
...
#endif
즉, CPU 사이클 카운트를 얻은 다음 미리 측정해 둔 ‘사이클당 초’를 곱해서 부팅 시점 기준 현재 시간을 얻는다. 부동소수점 타입이 신경 쓰이기는 하지만 이보다 효율적이기는 힘들 것 같다. 이 방식이 가능한 건 CPU가 절전 모드로 들어가거나 클럭이 크게 바뀔 리가 없고 각 스레드가 한 코어에 고정돼서 동작하기 때문이다. 더불어 가끔씩 호출되는 clib_time_verify_frequency()에서 clock_gettime()을 이용해 사이클당 초 값을 보정한다.
지금까지 살펴본 건 프로토콜 스택에서 쓰기 위한 효율성 중시 타이머이고, UI처럼 성능이 덜 중요한 곳에서 쓸 수 있는 ‘정상적인’ 타이머도 있다. 복잡한 구조 같은 거 없이 그냥 setitimer()를 쓴다.
저 위 vlib_main() 함수의 초기화 코드를 보면 “프로세스 타이밍 휠”이란 말이 나온다. 프로세스가 일정 간격으로 동작을 수행할 수 있게 하는 데에도 타이머가 쓰인다. 자, 이제 프로세스를 들여다볼 차례다.
프로세스
구현 메커니즘을 살펴보기에 앞서 vpp/src/vlib/vlib_process_doc.h 파일의 소개를 먼저 보자면:
협력적 다중 작업 스레드 지원.
vlib에서는 경량인 협력적 다중 작업 스레드 모델을 제공한다. 문맥 전환에 setjmp/longjmp 쌍만큼의 비용이 든다. vlib 스레드에서는 10us 동안 잠드는 것도 그리 이상한 게 아니다.
그래프 노드 스케줄러가 전통적인 벡터 처리 run-to-completion 그래프 노드와 거의 같은 방식으로 이 프로세스들을 호출한다. 스택 전환을 위해 필요한 setjmp/longjmp가 들어가거나 빠질 뿐이다.
vlib_node_registration_t의type필드를VLIB_NODE_TYPE_PROCESS로 설정하기만 하면 된다. 사실 프로세스는 부정확한 이름이다. 스레드가 맞다.작성 시점 현재 기본 스택 크기는 2«15, 즉 32kB다. 노드 등록에서
process_log2_n_stack_bytes멤버를 필요한 값으로 초기화 하면 된다. 그래프 노드 디스패처에서 스택 넘침을 탐지하기 위한 노력을 좀 하며, 각 스레드 스택 아래에 접근 불가 페이지를 맵 한다.프로세스 노드 디스패치 함수는 보통
while (1) { }루프이다. 루프에서 더 할 일이 없으면 실행을 중지하며, 지나치게 오래 실행해서는 안 된다. 지나치게 오래라는 건 응용에 따라 달라지는 개념이다. 여러 해에 걸쳐 우리는 시간 프레임 크기에 민감한 컨트롤 플레인 노드들을 만들었으며, 이 노드들은 시간 프레임이 작을 때 가용 CPU 대역폭을 더 많이 사용하게 된다. 전통적인 예가 포워딩 테이블 변경이다. 테이블 구축 프로세스가 포워딩 테이블을 유효한 상태로 두기만 한다면 테이블 구축 프로세스의 실행을 중지해서 컨트롤 플레인 활동으로 인한 패킷 버림을 막을 수 있다.프로세스 노드는 정해진 시간 동안, 또는 다른 개체가 이벤트를 알릴 때까지, 또는 둘 모두를 기다리며 실행을 중지할 수 있다. 아래 예를 보라.
VLIB 프로세스 문맥에서 돌 때 루프 불변 조건(invariant) 문제에 엄격히 신경을 써야 한다. 어떤 자료 구조에 접근하고 있으면서 실행이 중지될 수 있는 함수를 호출하는 경우 그 자료 구조가 구조 상 바뀔 수 없어야 한다. 많은 경우에서는 자료 구조의 스냅샷 사본을 만들어서 느긋하게 그 사본에 접근한 다음 사본을 해제하는 게 가장 낫다.
다음이 예이다.
#define EXAMPLE_POLL_PERIOD 10.0 static uword example_process (vlib_main_t * vm, vlib_node_runtime_t * rt, vlib_frame_t * f) { f64 poll_time_remaining; uword event_type, *event_data = 0; poll_time_remaining = EXAMPLE_POLL_PERIOD; while (1) { int i; // 다음 호출 주기까지, 또는 이벤트를 받을 때까지 // 잠들어 있기 // poll_time_remaining = vlib_process_wait_for_event_or_clock (vm, poll_time_remaining); event_type = vlib_process_get_events (vm, &event_data); switch (event_type) { case ~0: // 이벤트 아님 => 타임아웃 break; case EVENT1: for (i = 0; i < vec_len (event_data); i++) handle_event1 (vm, event_data[i]); break; case EVENT2: for (i = 0; i < vec_len (event_data); i++) handle_event2 (vm, event_data[i]); break; // 각 이벤트에 대해 이런 식으로... default: // 발생해서는 안 됨... clib_warning ("BUG: unhandled event type %d", event_type); break; } vec_reset_length (event_data); // 타이머 만료, 주기적으로 실행할 함수 호출 if (vlib_process_suspend_time_is_zero (poll_time_remaining)) { example_periodic (vm); poll_time_remaining = EXAMPLE_POLL_PERIOD; } } // NOTREACHED return 0; } static VLIB_REGISTER_NODE (example_node) = { .function = example_process, .type = VLIB_NODE_TYPE_PROCESS, .name = "example-process", };이 예에서 VLIB 프로세스 노드는 이벤트가 발생하거나 10초가 경과하기를 기다린다. 코드에서 이벤트 종류에 따라 적절한 핸들러 함수를 호출한다.
각
vlib_process_get_events호출은vlib_process_signal_event호출로 전달한 이벤트 종류별 데이터 벡터를 반환한다.vec_len (event_data) >= 1이다.event_data[0]만 처리하는 것은 오류이다.(
vec_free (...)를 호출하는 대신)vec_reset_length (event_data)호출로event_data벡터 길이를 0으로 재설정하는 건 이벤트 체계에서 반복적으로 이벤트 데이터 벡터를 할당하고 해제하느라 사이클을 날리지 않는다는 뜻이다. 흔한 코딩 패턴으로, 적절히 쓴다면 충분한 값어치가 있다.
위 코드에서 보듯 프로세스는 잠깐 실행하고 오래 기다리는 걸 반복한다. 모든 프로세스들을 다 합쳐도 CPU 시간을 별로 잡아먹지 않는다는 가정 하에 VPP에서는 모든 프로세스를 메인 스레드에서 실행한다. 그러면 구현과 동작에서 많은 게 단순해진다. 하지만 그 가정이 어긋나면, 즉 프로세스들이 CPU 시간을 많이 소모하면 메인 스레드의 패킷 스루풋이 뚝뚝 떨어지게 된다. 메인 스레드의 패킷 처리 부하를 줄여서 (가령 메인 스레드에게 인터페이스 수신 큐를 다른 스레드보다 적게 할당해서) 균형을 조정하는 게 가능할 수도 있지만, 귀찮은 일이다.
이전 포스트에서 실행 문맥을 만들고 전환하는 함수들을 슬쩍 살펴봤다. 그 함수들을 요래조래 조합하면 비선점형 스케줄링을 구현할 수 있다.
void main_loop(vm)
{
/* 프로세스들을 시작 */
foreach_process(p, vm->processes)
start_process(p);
while (1) {
/* 이런저런 일들을 하고 */
foreach_event(e, vm->event_queue) {
p = e->target_process;
/* 이벤트 데이터 전달은 귀찮으니 생략 */
resume_process(p);
}
}
}
void start_process(p)
{
getcontext(&p->process_ctx);
p->process_ctx.ss_sp = a_stack;
p->process_ctx.ss_size = a_stack_size;
p->process_ctx.uc_link = &p->main_ctx;
makecontext(&p->process_ctx, p->function, 0);
/* 프로세스 실행 시작! */
swapcontext(&p->main_ctx, &p->process_ctx);
/* 되돌아왔을 때 p는 대기 중이거나 실행을 마친 상태 */
}
void resume_process(p)
{
swapcontext(&p->main_ctx, &p->process_ctx);
}
void process_proc(void)
{
p->state = PROCESS_STATE_RUNNING;
/* 이런저런 일들을 하고 */
while (1) {
wait_for_event(p);
/* 반복 수행하는 짧은 작업 */
}
}
VLIB_NODE_REGISTER(process_node) = {
.function = process_proc,
.type = VLIB_NODE_TYPE_PROCESS,
.name = "sample-process",
};
void wait_for_event(p)
{
p->state = PROCESS_STATE_SUSPENDED;
swapcontext(&p->process_ctx, &p->main_ctx);
p->state = PROCESS_STATE_RUNNING;
}
대응하는 VPP 코드는 다음과 같다.
vpp/src/vlib/node.h:
typedef struct {
/* Node runtime for this process. */
vlib_node_runtime_t node_runtime;
/* Where to longjmp when process is done. */
clib_longjmp_t return_longjmp;
#define VLIB_PROCESS_RETURN_LONGJMP_RETURN ((uword) ~0 - 0)
#define VLIB_PROCESS_RETURN_LONGJMP_SUSPEND ((uword) ~0 - 1)
/* Where to longjmp to resume node after suspend. */
clib_longjmp_t resume_longjmp;
#define VLIB_PROCESS_RESUME_LONGJMP_SUSPEND 0
#define VLIB_PROCESS_RESUME_LONGJMP_RESUME 1
...
/* Process stack. Starts here and extends 2^log2_n_stack_bytes
bytes. */
#define VLIB_PROCESS_STACK_MAGIC (0xdead7ead)
u32 stack[0] ALIGN_ON_MULTIPLE_PAGE_BOUNDARY_FOR_MPROTECT;
} vlib_process_t __attribute__ ((aligned (CLIB_CACHE_LINE_BYTES)));
vpp/src/vlib/main.c:
static_always_inline void
vlib_main_or_worker_loop (vlib_main_t * vm, int is_main)
{
...
/* Start all processes. */
if (is_main)
{
uword i;
nm->current_process_index = ~0;
for (i = 0; i < vec_len (nm->processes); i++)
cpu_time_now = dispatch_process (vm, nm->processes[i], /* frame */ 0,
cpu_time_now);
}
while (1)
{
...
if (is_main)
{
nm->data_from_advancing_timing_wheel =
TW (tw_timer_expire_timers_vec)
((TWT (tw_timer_wheel) *) nm->timing_wheel, vlib_time_now (vm),
nm->data_from_advancing_timing_wheel);
if (PREDICT_FALSE
(_vec_len (nm->data_from_advancing_timing_wheel) > 0))
{
uword i;
processes_timing_wheel_data:
for (i = 0; i < _vec_len (nm->data_from_advancing_timing_wheel);
i++)
{
...
cpu_time_now =
dispatch_suspended_process (vm, di, cpu_time_now);
}
_vec_len (nm->data_from_advancing_timing_wheel) = 0;
}
}
for (i = 0; i < _vec_len (nm->pending_frames); i++)
cpu_time_now = dispatch_pending_node (vm, i, cpu_time_now);
_vec_len (nm->pending_frames) = 0;
/* Pending internal nodes may resume processes. */
if (is_main && _vec_len (nm->data_from_advancing_timing_wheel) > 0)
goto processes_timing_wheel_data;
...
}
}
static u64
dispatch_process (...)
{
...
n_vectors = vlib_process_startup (vm, p, f);
...
}
static_always_inline uword
vlib_process_startup (vlib_main_t * vm, vlib_process_t * p, vlib_frame_t * f)
{
vlib_process_bootstrap_args_t a;
uword r;
a.vm = vm;
a.process = p;
a.frame = f;
r = clib_setjmp (&p->return_longjmp, VLIB_PROCESS_RETURN_LONGJMP_RETURN);
if (r == VLIB_PROCESS_RETURN_LONGJMP_RETURN)
r = clib_calljmp (vlib_process_bootstrap, pointer_to_uword (&a),
(void *) p->stack + (1 << p->log2_n_stack_bytes));
return r;
}
static uword
vlib_process_bootstrap (uword _a)
{
vlib_process_bootstrap_args_t *a;
...
a = uword_to_pointer (_a, vlib_process_bootstrap_args_t *);
vm = a->vm;
p = a->process;
f = a->frame;
node = &p->node_runtime;
n = node->function (vm, node, f);
clib_longjmp (&p->return_longjmp, n);
return n;
}
static u64
dispatch_suspended_process (...)
{
...
n_vectors = vlib_process_resume (p);
...
}
static_always_inline uword
vlib_process_resume (vlib_process_t * p)
{
uword r;
p->flags &= ~(VLIB_PROCESS_IS_SUSPENDED_WAITING_FOR_CLOCK
| VLIB_PROCESS_IS_SUSPENDED_WAITING_FOR_EVENT
| VLIB_PROCESS_RESUME_PENDING);
r = clib_setjmp (&p->return_longjmp, VLIB_PROCESS_RETURN_LONGJMP_RETURN);
if (r == VLIB_PROCESS_RETURN_LONGJMP_RETURN)
clib_longjmp (&p->resume_longjmp, VLIB_PROCESS_RESUME_LONGJMP_RESUME);
return r;
}
vpp/src/vlib/node_funcs.h:
always_inline f64
vlib_process_wait_for_event_or_clock (vlib_main_t * vm, f64 dt)
{
...
p->flags |= (VLIB_PROCESS_IS_SUSPENDED_WAITING_FOR_EVENT
| VLIB_PROCESS_IS_SUSPENDED_WAITING_FOR_CLOCK);
r = clib_setjmp (&p->resume_longjmp, VLIB_PROCESS_RESUME_LONGJMP_SUSPEND);
if (r == VLIB_PROCESS_RESUME_LONGJMP_SUSPEND)
{
p->resume_clock_interval = dt * 1e5;
clib_longjmp (&p->return_longjmp, VLIB_PROCESS_RETURN_LONGJMP_SUSPEND);
}
return wakeup_time - vlib_time_now (vm);
}
always_inline void *
vlib_process_signal_event_helper (...)
{
...
if (add_to_pending)
{
u32 x = vlib_timing_wheel_data_set_suspended_process (n->runtime_index);
p->flags = p_flags | VLIB_PROCESS_RESUME_PENDING;
vec_add1 (nm->data_from_advancing_timing_wheel, x);
if (delete_from_wheel)
TW (tw_timer_stop) ((TWT (tw_timer_wheel) *) nm->timing_wheel,
p->stop_timer_handle);
}
return data_to_be_written_by_caller;
}
프로세스 시작 때의 getcontext()-makecontext()-swapcontext() 조합이 clib_setjmp()-clib_calljmp() 조합에 대응하고, 메인 루프 문맥과 프로세스 문맥 사이를 오갈 때의 swapcontext()가 clib_setjmp()-clib_longjmp() 조합에 대응한다. clib_setjmp()와 clib_longjmp()는 전통적인 setjmp()/longjmp()를 간략히 재구현하면서 제약(스택을 되감는 방향으로만 점프 가능)을 없앤 것이다. 그리고 clib_calljmp()는 원하는 함수를 새 스택에서 실행하는 기능을 새로 만든 것이다. VPP 소스 트리의 longjmp.S 파일에 소스가 있다. 간략하다.
한 턴을 마친 프로세스는 (다른 프로세스나 패킷 처리 루틴에서 보낸) 이벤트 수신이나 타이머 만료를 기다린다. 프로세스에서 다른 프로세스로 이벤트를 보내는 건 간단히 구현할 수 있다. 이벤트 큐(nm->data_from_advancing_timing_wheel)에 알림 항목을 집어넣기만 하면 된다. 그러면 잠시 후 메인 루프에서 큐를 확인하고서 dispatch_suspended_process()로 프로세스를 깨운다. 타임아웃 처리도 비교적 간단하다. 메인 루프에서 TW (tw_timer_expire_timers_vec)를 호출해서 만료된 타이머를 알아낸 다음 해당 프로세스에게 ‘타이머 만료’ 이벤트를 보내면 된다. 그럼 남는 건 패킷 처리 스레드에서 메인 스레드의 프로세스에게 이벤트를 보내는 메커니즘이다.
어떻게든 메인 스레드에서 이벤트 보내기 함수가 호출되도록 하면 된다. 계층은 좀 다르지만 프로세서 간 인터럽트(IPI)와 비슷한 메커니즘이 필요한 셈이다. 어떻게 해야 다른 스레드에서 원하는 함수가 호출되게 할 수 있을까? 다른 스레드에서 원하는 함수가 호출되게 하는 거니까 remote procedure call, 즉 일종의 RPC 메커니즘이 필요하다. VPP에서는 공유 메모리를 통신 매체로 하는 RPC 메커니즘을 제공한다.
vpp/src/vlib/threads.c:
void *rpc_call_main_thread_cb_fn;
void
vlib_rpc_call_main_thread (void *callback, u8 * args, u32 arg_size)
{
if (rpc_call_main_thread_cb_fn)
{
void (*fp) (void *, u8 *, u32) = rpc_call_main_thread_cb_fn;
(*fp) (callback, args, arg_size);
}
else
clib_warning ("BUG: rpc_call_main_thread_cb_fn NULL!");
}
vpp/src/vlibmemory/memory_vlib.c:
extern void *rpc_call_main_thread_cb_fn;
static clib_err_t *
rpc_api_hookup (vlib_main_t * vm)
{
...
rpc_call_main_thread_cb_fn = vl_api_rpc_call_main_thread;
return 0;
}
void
vl_api_rpc_call_main_thread (void *fp, u8 *data, u32 data_length)
{
vl_api_rpc_call_main_thread_inline (fp, data, data_length, /*force_rpc */
0);
}
always_inline void
vl_api_rpc_call_main_thread_inline (void *fp, u8 * data, u32 data_length,
u8 force_rpc)
{
vl_api_rpc_call_t *mp;
...
/* Main thread: call the function directly */
if ((force_rpc == 0) && (vlib_get_thread_index () == 0))
{
vlib_main_t *vm = vlib_get_main ();
void (*call_fp) (void *);
vlib_worker_thread_barrier_sync (vm);
call_fp = fp;
call_fp (data);
vlib_worker_thread_barrier_release (vm);
return;
}
/* Any other thread, actually do an RPC call... */
mp = vl_msg_api_alloc_as_if_client (sizeof (*mp) + data_length);
memset (mp, 0, sizeof (*mp));
clib_memcpy (mp->data, data, data_length);
mp->_vl_msg_id = ntohs (VL_API_RPC_CALL);
mp->function = pointer_to_uword (fp);
mp->need_barrier_sync = 1;
...
vl_msg_api_send_shmem_nolock (q, (u8 *) & mp);
...
}
보내는 쪽이 있으면 받는 쪽이 있어야 한다. 메인 스레드에서 도는 프로세스 노드 하나가 RPC 요청을 수신해서 타입별 핸들러를 실행한다.
static uword
memclnt_process (...)
{
...
while (1)
{
...
vl_msg_api_handler_with_vm_node (am, (void *) mp, vm, node);
...
}
...
}
VLIB_REGISTER_NODE (memclnt_node) =
{
.function = memclnt_process,
.type = VLIB_NODE_TYPE_PROCESS,
.name = "api-rx-from-ring",
.state = VLIB_NODE_STATE_DISABLED,
};
static void
vl_api_rpc_call_t_handler (vl_api_rpc_call_t * mp)
{
vl_api_rpc_call_reply_t *rmp;
int (*fp) (void *);
i32 rv = 0;
vlib_main_t *vm = vlib_get_main ();
if (mp->function == 0)
{
rv = -1;
clib_warning ("rpc NULL function pointer");
}
else
{
if (mp->need_barrier_sync)
vlib_worker_thread_barrier_sync (vm);
fp = uword_to_pointer (mp->function, int (*)(void *));
rv = fp (mp->data);
if (mp->need_barrier_sync)
vlib_worker_thread_barrier_release (vm);
}
...
}
임의 스레드에서 특정 프로세스에게 이벤트를 보내고 싶으면 이벤트 보내기 함수를 인자로 해서 vlib_rpc_call_main_thread()를 호출하면 된다. 그러면 RPC 메커니즘을 통해 메인 스레드에서 그 함수가 호출되고, 거기서부터는 평범한 프로세스 간 이벤트 전송이다. 여기서 가장 구현하기 까다로운 부분은 아마 메인 스레드에서 RPC 요청을 받는 프로세스 함수(memclnt_process())일 것이다. 마찬가지로 프로세스니까 짧게 실행하고 CPU를 양보해야 하는데, 그때 타임아웃 시간을 얼마로 주느냐에 따라 CPU 소모 정도와 이벤트 전달 지연이 달라진다.
이전 포스트에서 패킷 처리 노드를 살펴봤고 이번에 타이머와 프로세스 실행 구조를 둘러봤으니 중요한 뼈대는 끝났다. VPP 시리즈를 마무리하는 다음 포스트에서는 나머지 잡다한 내용들을 다룬다.
