비동기 암호 연산
극세사로 짠 OpenSSL
현재 OpenSSL의 최신 안정 버전은 1.1.1과 1.1.0i이다. 2016년 8월에 1.0.2h에서 1.1.0으로 도약할 때 ChaCha20/Poly1305/CCM 지원 추가 등에 더해서 동작 구조와 관련된 변화가 좀 있었다.
https://www.openssl.org/news/cl110.txt:
- ASYNC 지원 추가. libcrypto에 이제 async 모듈이 포함돼서 비동기 가능 엔진을 사용하면 암호 연산을 비동기적으로 수행할 수 있음. 더 자세한 내용은 ASYNC_start_job() 맨페이지 참고. libssl에도 이 기능이 들어갔으며 새 모드 SSL_MODE_ASYNC와 관련 오류 SSL_ERROR_WANT_ASYNC가 도입됐음. SSL_CTX_set_mode() 및 SSL_get_error() 맨페이지 참고. Intel Corp.과 협력해서 개발했음. [Matt Caswell]
- AFALG 엔진 추가. 작업을 리눅스 커널로 오프로드 할 수 있는 비동기 가능 엔진임. 이 최초 버전에서는 AES128-CBC만 지원함. 커널 버전이 4.1.0 이상이어야 함. [Catriona Lucey]
- “파이프라이닝” 지원 추가. EVP_CIPH_FLAG_PIPELINE 플래그가 설정돼 있는 암호는 여러 암호화/복호화를 동시에 처리할 능력이 있는 것임. 현재 내장 암호들 중에는 이 특성을 가진 게 없지만 엔진들에서 이 기능을 제공해서 스루풋을 크게 개선할 수 있을 것으로 예상됨. 지원을 libssl까지 확장해서 한 연결의 여러 레코드를 한번에 처리할 수 있도록 함 (>=TLS 1.1). [Matt Caswell]
파이프라이닝도 재밌어 보이지만 이번 주제는 비동기 동작이다. (근데 그 둘이 무관하지는 않다. 비동기 동작 하에서 파이프라이닝이 의미가 있다.)
일단 ASYNC_start_job()과 ASYNC_WAIT_CTX_new() 맨페이지를 참고할 수 있다. 실보다 가는 초록색 섬유인데 POSIX 시스템에서는 makecontext()/setcontext()를 이용한다. 코루틴 얘기에 등장했던 문맥 전환 함수들인데, 파이버를 프로그래밍 언어의 어휘로 만든 게 코루틴이니 그렇다.
일반적인 동작 구조는 간단하다. 세션이 생길 때 새 파이버를 만든다. 메인 파이버가 루프를 돌며 새 이벤트(예: 소켓에 수신 데이터 있음)를 확인하다가 이벤트가 발생하면 대응하는 작업 파이버로 전환한다. 작업 파이버에서 이런저런 동작을 하다가 기약 없이 기다려야 할 때가 오면 (예: recv()가 EAGAIN 반환) 다시 메인 파이버로 전환한다. 메인 스레드에서 이벤트를 감시하며 실행 흐름을 통제한다는 점에선 논블록 소켓에 poll() 계열 I/O 다중화 함수를 쓰는 프로그램과 비슷하지만 작업 스레드의 동작 코드를 선형적으로 작성할 수 있다는 점에선 세션마다 스레드를 만드는 방식과 비슷하다. 문맥 전환 비용은 비자발적 스케줄링 방식보다 훨씬 작지만 파이버마다 문맥(스택 + 레지스터 셋)을 유지하기 때문에 메모리 사용량은 큰 차이가 없다.
이걸 어디에 써먹을까? 세션마다 스레드를 한 개씩 생성하는 프로그램이 있다면 파이버로 바꿔서 동작 효율성을 좀 높일 수 있다. 하지만 성능에 제대로 신경을 쓴 프로그램이라면 I/O 다중화 함수를 쓰는 이벤트 주도 구조일 것이고 그걸 굳이 파이버 방식으로 바꾸는 건 득보다 실이 클 수도 있다. 그런데도 인텔까지 나서서 OpenSSL에 비동기 동작 구조를 도입한 건 암호 연산 전용 하드웨어를 비동기 방식으로 쓸 수 있게 하기 위해서이다. 즉 QAT용 엔진을 위한 작업이다.
암호 연산을 더 빠르게
암호 연산 하드웨어를 비동기로 사용하려는 이유는 뭘까? 성능, 구체적으로는 스루풋이다.
HTTPS 지원 웹 서버부터 IPsec 게이트웨이까지 암호화를 하는 응용의 성능에 가장 큰 영향을 끼치는 건 보통 암호 연산이다. 연산 비용이 낮으면 공격하기도 쉬우니까 연산 비용이 충분히 커야 되는데, 현재 가용 자원으로 공격에 걸리는 평균 시간이 일정 이상이 되도록 연산 난이도(가령 키 길이)를 정한다. 그러니 CPU들의 클럭이 올라갈수록 바이트당 사이클이 늘어나야 한다. 반면 암호화 외의 코드를 실행하는 데 드는 사이클은 새로운 기능이 추가되지 않는 한 크게 변하지 않는다. 따라서 전체적인 CPU 속도가 올라가면 암호화에 쓰는 CPU 시간의 상대적 비율이 커지게 된다. (물론 현실은 다를 수 있다. 새로 생긴 여유 클럭을 낭비할 수 있는 다른 방법은 많다.) 즉 암호 연산은 비싸고, 그 비용을 줄이려는 노력은 계속될 수밖에 없다. 거시적으로는 또 다른 붉은 여왕 이야기가 될 뿐이더라도.
요새 많이 쓰는 방식은 범용 CPU에 암호 연산을 위한 인스트럭션을 추가하는 것이다. 인텔에 AES-CLMUL-SHA 확장이, VIA에 Padlock이, 기타 여러 CPU들에 전용 인스트럭션이 있다. 보통 몇 배 수준으로 연산 시간이 줄어든다. 응용이 소모하는 사이클 전체에서 암호 연산을 뺀 부분의 비율이 높아지므로 거기서 최적화를 할 여지가 좀 생긴다. 한편으로 결국은 CPU에서 그 인스트럭션을 실행하는 거라서 비동기 동작 구조와 별 관련이 없다. 겉으로 드러나는 인터페이스가 순수 소프트웨어 구현과 거의 같기에 간편하게 사용할 수 있다. 하지만 안그래도 복잡한 CPU에 새 인스트럭션을 추가하는 건 쉽지 않은 일이기에 많이 쓸 만한 알고리즘 몇 가지만 구현하게 된다. (Cavium OCTEON처럼 여러 알고리즘을 지원하는 경우도 있기는 하다.)
좀 더 전통적인 방식은 암호 연산 전용 프로세서를 쓰는 것이다. 보통은 PCI 등의 버스로 연결된 확장 장치 형태지만 CPU에 더 가까울 수도 있다. 여러 알고리즘을 지원하는 게 일반적이고 실행 시간이 길거나 불확정인 연산(가령 비대칭 키 쌍 생성)도 수월하게 지원할 수 있다. 전용 프로세서라고 마법처럼 빠를 수는 없는 법이고 개별 연산 수준에서는 전용 인스트럭션과 비슷한 속도를 기대할 수 있다. 대신 장치 내 병렬 처리로 스루풋을 높이며, 더 높은 스루풋이 필요하면 장치를 여럿 설치하면 된다. 암호 연산을 호출하는 곳과 수행하는 곳이 멀어지게 되므로 둘 사이 통신 오버헤드가 크다면 따로 장치를 쓰는 게 무의미해질 수도 있다.
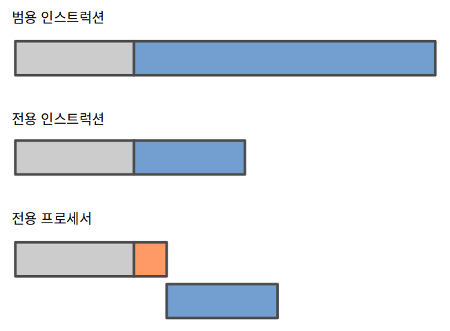
클라이언트에서는 간편한 전용 인스트럭션 방식이 적당하다. 반면 여러 알고리즘을 높은 스루풋으로 처리해야 하는 서버나 미들박스에선 전용 장치 방식이 좋을 수 있다. 물론 전체 사이클 소모에서 암호 연산이 차지하는 비율이나 소프트웨어 쪽 추가 작업량 등의 요소를 함께 고려해야 한다.
(암복호화를 NIC에서 수행하는 방식도 있다. 나름의 장점과 한계가 있다.)
전용 장치와 프로그램 동작 구조
전용 장치로 작업을 오프로드 하는 게 성능 향상으로 이어지려면 암호 연산을 수행하는 동안 CPU가 다른 유용한 작업을 해야 된다. 요청을 보내고 응답이 올 때까지 맴돌며 기다린다면 순수 소프트웨어 구현보다 떨어지는 성능이 나올 수도 있다. 벤치마크 결과(STH, Intel)를 보면 동기 vs 비동기 차이와 함께 여러 성능 특성을 볼 수 있다.
암호 연산과 병렬로 CPU가 다른 일을 할 수 있으려면 암호 연산 전에 멈췄던 실행 흐름이 연산 완료 후의 실행 흐름으로 이어질 수 있어야 한다. 즉 어떤 형태건 스케줄링이 필요하다. 가장 먼저 떠올릴 수 있는 방식은 운영체제에서 스케줄링을 하는 것이다. 다음은 글머리에 슬쩍 등장했던 AFALG의 코드이다.
linux/crypto/algif_skcipher.c:
static int _skcipher_recvmsg(struct socket *sock, struct msghdr *msg,
size_t ignored, int flags)
{
...
if (msg->msg_iocb && !is_sync_kiocb(msg->msg_iocb)) {
/* AIO operation */
...
skcipher_request_set_callback(&areq->cra_u.skcipher_req,
CRYPTO_TFM_REQ_MAY_SLEEP,
af_alg_async_cb, areq);
err = ctx->enc ?
crypto_skcipher_encrypt(&areq->cra_u.skcipher_req) :
crypto_skcipher_decrypt(&areq->cra_u.skcipher_req);
/* AIO operation in progress */
if (err == -EINPROGRESS || err == -EBUSY)
return -EIOCBQUEUED;
sock_put(sk);
} else {
/* Synchronous operation */
skcipher_request_set_callback(&areq->cra_u.skcipher_req,
CRYPTO_TFM_REQ_MAY_SLEEP |
CRYPTO_TFM_REQ_MAY_BACKLOG,
crypto_req_done, &ctx->wait);
err = crypto_wait_req(ctx->enc ?
crypto_skcipher_encrypt(&areq->cra_u.skcipher_req) :
crypto_skcipher_decrypt(&areq->cra_u.skcipher_req),
&ctx->wait);
}
...
}
linux/include/linux/crypto.h:
static inline int crypto_wait_req(int err, struct crypto_wait *wait)
{
switch (err) {
case -EINPROGRESS:
case -EBUSY:
wait_for_completion(&wait->completion);
reinit_completion(&wait->completion);
err = wait->err;
break;
}
return err;
}
linux/crypto/af_alg.c:
void af_alg_async_cb(struct crypto_async_request *_req, int err)
{
struct af_alg_async_req *areq = _req->data;
struct sock *sk = areq->sk;
struct kiocb *iocb = areq->iocb;
unsigned int resultlen;
/* Buffer size written by crypto operation. */
resultlen = areq->outlen;
af_alg_free_resources(areq);
sock_put(sk);
iocb->ki_complete(iocb, err ? err : resultlen, 0);
}
linux/crypto/api.c:
void crypto_req_done(struct crypto_async_request *req, int err)
{
struct crypto_wait *wait = req->data;
if (err == -EINPROGRESS)
return;
wait->err = err;
complete(&wait->completion);
}
_skcipher_recvmsg()의 동기 연산 경로에서 crypto_skcipher_{en,de}crypt()를 호출하면 거기서 적절한 암호 모듈의 encrypt/decrypt 함수를 호출하고, 그 모듈이 비동기 연산을 지원하면 (예: 다른 CPU로 연산을 오프로드 하는 pcrypt) -EINPROGRESS를 반환하고, 그러면 crypto_wait_req()에서 태스크가 잠이 든다. 잠시 후 연산이 완료되면 미리 설정해 둔 콜백 crypto_req_done()이 호출돼서 태스크가 깨어난다.
운영체제에게 맡기는 방식은 편리하지만 상당한 오버헤드를 감수해야 한다. 태스크를 재우고 깨우는 비용이 크고 두 공간을 오가는 비용도 크다. 한편으로 위 코드에 슬쩍 등장하는 AIO API를 쓰면 태스크 전환 횟수를 줄일 가능성이 생기고, 거기에 vmsplice() 등을 더하면 데이터가 문맥을 넘나드는 비용을 줄일 수 있다. 요컨데 사용자 쪽에 복잡성을 좀 더해서 성능을 꽤 개선할 수 있지만 구조에서 오는 한계는 남는다. (OpenSSL의 AFALG 엔진에서 AIO를 쓴다.)
파이버 같은 가벼운 스케줄링 기법을 쓰면 스케줄링 오버헤드를 최대한 줄일 수 있고 UIO를 활용하면 문맥을 넘나드는 비용을 없애거나 줄일 수 있다. OpenSSL에 추가된 ASYNC 모듈이 전자에 해당하고 QAT 엔진 아래에서 도는 QAT 드라이버가 UIO 사용자 공간 드라이버다. (리눅스 커널 소스에 포함된 QAT 드라이버는 UIO를 지원하지 않는다. 인텔에서 제공하는 드라이버에 포함된 커널 드라이버를 써야 한다.)
QAT_Engine/qat_ciphers.c:
int qat_chained_ciphers_do_cipher(EVP_CIPHER_CTX *ctx, unsigned char *out,
const unsigned char *in, size_t len)
{
...
if (!INIT_SEQ_IS_FLAG_SET(qctx, INIT_SEQ_QAT_SESSION_INIT)) {
...
sts = cpaCySymInitSession(..., qat_chained_callbackFn, ...);
...
}
...
do {
...
sts = qat_sym_perform_op(...);
if (sts != CPA_STATUS_SUCCESS) {
...
break;
}
/* Increment after successful submission */
done.num_submitted++;
} while (++pipe < qctx->numpipes);
...
do {
if(done.opDone.job != NULL) {
/* If we get a failure on qat_pause_job then we will
not flag an error here and quit because we have
an asynchronous request in flight.
We don't want to start cleaning up data
structures that are still being used. If
qat_pause_job fails we will just yield and
loop around and try again until the request
completes and we can continue. */
if ((job_ret = qat_pause_job(done.opDone.job, 0)) == 0)
pthread_yield();
} else {
pthread_yield();
}
} while (!done.opDone.flag ||
QAT_CHK_JOB_RESUMED_UNEXPECTEDLY(job_ret));
...
}
CpaStatus qat_sym_perform_op(int inst_num,
void *pCallbackTag,
const CpaCySymOpData * pOpData,
const CpaBufferList * pSrcBuffer,
CpaBufferList * pDstBuffer,
CpaBoolean * pVerifyResult)
{
CpaStatus status;
op_done_t *opDone = (op_done_t *)pCallbackTag;
unsigned int uiRetry = 0;
useconds_t ulPollInterval = getQatPollInterval();
int iMsgRetry = getQatMsgRetryCount();
do {
status = cpaCySymPerformOp(qat_instance_handles[inst_num],
pCallbackTag,
pOpData,
pSrcBuffer,
pDstBuffer,
pVerifyResult);
if (status == CPA_STATUS_RETRY) {
if (opDone->job) {
if ((qat_wake_job(opDone->job, 0) == 0 ||
(qat_pause_job(opDone->job, 0) == 0)) {
...
status = CPA_STATUS_FAIL;
break;
}
} else {
qatPerformOpRetries++;
if (uiRetry >= iMsgRetry
&& iMsgRetry != QAT_INFINITE_MAX_NUM_RETRIES) {
...
status = CPA_STATUS_FAIL;
break;
}
uiRetry++;
usleep(ulPollInterval +
(uiRetry % QAT_RETRY_BACKOFF_MODULO_DIVISOR));
}
}
}
while (status == CPA_STATUS_RETRY);
return status;
}
static void qat_chained_callbackFn(void *callbackTag, CpaStatus status,
const CpaCySymOp operationType,
void *pOpData, CpaBufferList *pDstBuffer,
CpaBoolean verifyResult)
{
op_done_pipe_t *opdone = (op_done_pipe_t *)callbackTag;
CpaBoolean res = CPA_FALSE;
...
opdone->num_processed++;
res = (status == CPA_STATUS_SUCCESS) && verifyResult ? CPA_TRUE : CPA_FALSE;
...
/* The QAT API guarantees submission order for request
* i.e. first in first out. If not all requests have been
* submitted or processed, wait for more callbacks.
*/
if ((opdone->num_submitted != opdone->num_pipes) ||
(opdone->num_submitted != opdone->num_processed))
return;
...
/* Mark job as done when all the requests have been submitted and
* subsequently processed.
*/
opdone->opDone.flag = 1;
if (opdone->opDone.job) {
qat_wake_job(opdone->opDone.job, 0);
}
}
QAT_Engine/qat_events.c:
int qat_setup_async_event_notification(int notificationNo)
{
/* We will ignore notificationNo for the moment */
ASYNC_JOB *job;
ASYNC_WAIT_CTX *waitctx;
OSSL_ASYNC_FD efd;
void *custom = NULL;
if ((job = ASYNC_get_current_job()) == NULL) {
WARN("Could not obtain current job\n");
return 0;
}
if ((waitctx = ASYNC_get_wait_ctx(job)) == NULL) {
...
}
if (ASYNC_WAIT_CTX_get_fd(waitctx, engine_qat_id, &efd,
&custom) == 0) {
efd = eventfd(0, EFD_NONBLOCK);
...
if (ASYNC_WAIT_CTX_set_wait_fd(waitctx, engine_qat_id, efd,
custom, qat_fd_cleanup) == 0) {
...
}
}
return 1;
}
int qat_pause_job(volatile ASYNC_JOB *job, int notificationNo)
{
/* We will ignore notificationNo for the moment */
ASYNC_WAIT_CTX *waitctx;
OSSL_ASYNC_FD efd;
void *custom = NULL;
uint64_t buf = 0;
int ret = 0;
if (ASYNC_pause_job() == 0) {
...
}
if ((waitctx = ASYNC_get_wait_ctx((ASYNC_JOB *)job)) == NULL) {
...
}
if ((ret = ASYNC_WAIT_CTX_get_fd(waitctx, engine_qat_id, &efd,
&custom)) > 0) {
if (read(efd, &buf, sizeof(uint64_t)) == -1) {
...
/* Not resumed by the expected qat_wake_job() */
return QAT_JOB_RESUMED_UNEXPECTEDLY;
}
}
return ret;
}
int qat_wake_job(volatile *ASYNC_JOB *job, int notificationNo)
{
/* We will ignore notificationNo for the moment */
ASYNC_WAIT_CTX *waitctx;
OSSL_ASYNC_FD efd;
void *custom = NULL;
/* Arbitary value '1' to write down the pipe to trigger event */
uint64_t buf = 1;
int ret = 0;
if ((waitctx = ASYNC_get_wait_ctx((ASYNC_JOB *)job)) == NULL) {
...
}
if ((ret = ASYNC_WAIT_CTX_get_fd(waitctx, engine_qat_id, &efd,
&custom)) > 0) {
if (write(efd, &buf, sizeof(uint64_t)) == -1) {
...
}
}
return ret;
}
eventfd()도 등장하고 복잡한데, 결국은 장치로 연산 요청을 보낸 다음 ASYNC_pause_job()으로 문맥 바꿔서 다른 일 하다가 연산 완료 콜백을 통해 깨어나면 아까 멈췄던 지점부터 실행을 재개한다는 스토리다. 기본 동작 구조는 간단하지만 다뤄야 하는 기술적 이슈들이 좀 있다.
일단 암호 장치에서 연산이 완료됐는지 알 방법이 필요한데, 개념 증명 프로젝트인 “비동기 모드 Nginx”의 QAT 모듈 소스를 참고할 수 있다. 여러 방식이 있는데 결국은 이벤트 알림 아니면 폴링이다. 세부적으로는 어느 실행 흐름에서 폴링을 수행할 것인가 정도의 선택지가 있다.
또 다른 이슈는 응용과 장치 사이 경로에서 데이터 복사를 줄이는 것인데, 별도의 커널 모듈로 DMA 가능한 공유 메모리 덩어리를 할당받아서 쪼개 쓴다. 그 메모리와 응용 메모리 사이에서 여전히 복사가 이뤄지기는 하겠지만 데이터가 장치에 갔다 오는 과정에서는 복사가 없다. 한편 이런저런 사정으로 실행 흐름이 복잡해지면 자원 관리도 어려워진다. 장치에서 접근하는 메모리 공간을 연산 수행 중에 유효하게 유지해야 하고 연산이 끝난 후에는 잘 회수해야 한다.
이 정도로 끝인가 하면, 더 있다. 암호 장치의 입력 큐 크기가 유한할 테니 흐름 제어가 필요하다. 입력 큐가 가득 차면 앞쪽 생산 루틴 실행을 멈췄다가 큐에 공간이 생기면 재개해야 한다. 또한 장치 내부에서 병렬 처리를 한다면 요청들이 간 순서와 응답들이 돌아오는 순서가 다를 수도 있다. IPsec 내지 DTLS 데이터그램을 처리하는 응용이라면 그런 경우들이 생기더라도 호스트 외부의 망에서 일어났던 일인 양 스리슬쩍 넘어갈 수도 있겠지만 대부분의 응용에서는 어떻게든 대응을 해야 한다. 메시지 유실이나 변조까지는 고려하지 않아도 되는 게 그나마 다행이다.
OpenSSL용 QAT 엔진은 기존의 범용적이고 단순한 사용자 방향 인터페이스에 스스로를 맞춰야 하고, 그래서 여러 기술적 이슈들을 캡슐 안에 감추면서 동시에 동작 구조 변환(비동기적으로 이벤트가 발생하는 구조를 선형 실행 소비자가 데이터를 당겨 가는 구조에 맞추기)까지 한다. 많은 일을 하려니 복잡해지고 일부 이슈는 감추려 해도 상위 계층으로 새어 나간다. QAT 엔진보다 훨씬 단순한 AFALG 엔진에서도 AIO와 파이버를 연결하는 게 복잡성과 오버헤드의 주된 원천이다.
문제의 근원은 OpenSSL의 API를 (즉 동작 구조를) 유지한 채로 비동기 암호 연산을 가능하게 하려는 데 있다. 그러자니 TLS/암호 라이브러리 안에 스케줄링 모듈이 있는 낯선 구조가 생긴다. 그러는 대신 상위 계층으로 많은 걸 드러내고 또 넘기면 라이브러리/엔진/드라이버가 꽤 간단해질 수 있는데, 가령 DPDK의 QAT 드라이버 코드를 보면 OpenSSL 엔진과의 차이를 확연히 느낄 수 있다. 암호 장치 드라이버는 send/recv 인터페이스를 제공할 뿐이고 나머지는 상위 계층에서 알아서 한다. 위에서 할 일이 많아지지만 오버헤드를 줄일 가능성이 생긴다.
어떤 구조가 됐건 암호 장치 드라이버 위에 있는 건 IPsec처럼 단순한 데이터그램 기반 스택일 수도 있지만 TLS처럼 좀 더 복잡한 스택일 수도 있다.
TLS 스택의 동작 구조
일반적인 운영체제 구현에서 커널 네트워크 스택의 수신 경로를 보면 전송 계층 수신 큐를 기준으로 동작 구조가 달라진다. 앞쪽은 네트워크 장치 수신 인터럽트에서 시작해서 메시지를 미는 실행 흐름이고 뒤쪽은 소켓 API를 통해 응용이 당겨 가는 실행 흐름이다. 반면 송신 경로에는 그런 방향 전환이 없다. 또한 응용에서 수신 메시지를 당겨 간 다음에 메시지 종류에 따라 핸들러 함수를 호출하는 (즉 메시지를 밀어 넣는) 구조가 일반적인 걸 생각하면 recv() 시스템 호출이 동작하는 구간은 꽤 특이하다고 할 수 있다. (물론 그렇게 한 이유가 있다. 실행 흐름 분리와 격리를 위해서다.)
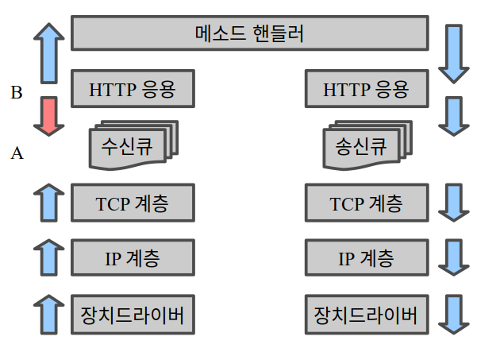
방향이 바뀌는 지점들을 아래로 밀어서 A 지점은 아예 밖으로 보내 버리고 B 지점을 장치 드라이버 바로 위에 둔 게 DPDK 같은 폴링 방식 프레임워크다. 프로그램에서 각종 초기화를 한 다음 진입하는 폴링 루프가 B 지점에 해당한다.
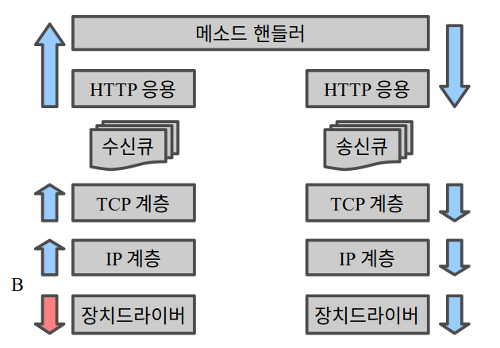
(경로에서 큐를 없애버릴 수 있으면 좋겠지만 ARQ를 위해 적어도 하나는 있어야 한다. 또 경로에 암호 장치가 끼어들면 더 필요할 수도 있다.)
다시 일반적인 실행 구조를 살펴 보면, TLS는 마침 전송 계층과 응용 사이에 있다. 즉 생각하기에 따라 당기는 모양으로 만들 수도 있고 미는 모양으로 만들 수도 있다. (이도 저도 아닌 OpenSSL ASYNC는 잊자.)
int tls_recv(buf, ...)
{
msg = net_recv(...);
parse_msg(msg);
if (is_msg_completed(msg)) {
process_msg(msg);
if (is_msg_encrypted(msg)) {
send_to_crypto(msg);
recv_from_crypto(buf);
} else {
memcpy(buf, msg);
}
return msg.len;
}
/* -EAGAIN 반환, 또는 재시도 */
}
void tls_on_recv_from_net(msg, ...)
{
parse_msg(msg);
if (is_msg_completed(msg)) {
process_msg(msg);
if (is_msg_encrypted(msg)) {
send_to_crypto(msg);
pause_recv_from_net();
} else {
to_next_layer(msg);
}
}
}
void tls_on_recv_from_crypto(msg, ...)
{
resume_recv_from_net();
to_next_layer(msg);
}
void to_next_layer(msg)
{
// send_to_app(msg); /* 상위 계층의 on_recv() 호출 */
// set_next_node(msg, ...); /* e.g. in VPP */
}
확실히 미는 쪽이 더 복잡하다. 게다가 통일된 인터페이스도 없다. 그래서인지 이름 있는 TLS 라이브러리들은 모두 당기는 구조다.
당기는 구조로 된 TLS 라이브러리를 미는 구조로 된 프로그램에서 써야 한다면 살짝 변환을 해 주면 된다.
void tls_on_recv_from_net_wrapper(msg, ...)
{
feed_msg_to_memory_bio(msg);
tls_recv(buf, ...);
send_to_app(buf);
}
파일 I/O 인터페이스로 메모리 데이터에 접근할 수 있게 해 주는 (fmemopen()과 비슷하지만 그보다 낮은 계층의) 메커니즘을 갖추고, 수신 메시지를 그리 넣어 준 다음 tls_recv()를 호출하면 내부적으로 네트워크 소켓 대신 그 메모리 버퍼에서 데이터를 읽는다. OpenSSL에는 메모리 BIO가 있고 다른 TLS 라이브러리들에도 함수 콜백 등의 형태로 비슷한 메커니즘이 있다.
미는 구조로 돼 있는 TLS 라이브러리를 당기는 구조에 맞추는 것도 가능하다.
void to_next_layer(msg)
{
enqueue(msg, ctx.recv_q);
if (is_queue_full(ctx.recv_q))
pause_recv(ctx.base_sock);
}
int tls_recv_wrapper(buf, ...)
{
was_full = is_queue_full(ctx.recv_q);
msg = dequeue_from_queue(ctx.recv_q);
memcpy(buf, msg);
if (was_full)
resume_recv(ctx.base_sock);
}
void main_loop()
{
...
if (is_readable(base_sock)) {
recv(base_sock, buf);
tls_on_recv_from_net(buf, ...);
}
if (is_readable(crypto_sock)) {
recv(crypto_sock, buf);
tls_on_recv_from_crypto(buf, ...);
}
if (!is_queue_empty(ctx.recv_q)) {
tls_recv_wrapper(buf, ...);
/* 기존의 응용 처리 */
}
...
}
어느 방향의 변환이든 데이터 복사 오버헤드가 더해지니 TLS 라이브러리와 응용이 동작 구조가 같은 게 좋다. 바로 그래서 주요 TLS 라이브러리들이 모두 당기는 구조인 것이고, 또 그래서 암호 연산 비동기 수행을 고려한 미는 구조의 TLS 라이브러리가 하나쯤 나올 때가 된 것이다.
부록: 관련 구현체
비동기 동작 구조와 TLS가 겹치는 영역에 여러 가지 구현체가 있다.
libevent에서는 기본 이벤트 전달 구조 위에 bufferevent라는 계층(들)을 덧붙일 수 있다. bufferevent의 원래 의도는 버퍼링이지만 필터링 등의 다양한 기능을 수행하도록 만들 수 있고, 그래서 VPP의 노드와 좀 비슷하기도 한데, 가장 최근에 추가된 게 TLS bufferevent다. 근데 libevent에서는 poll()까지만 수행하고 사용자측 콜백에서 recv()를 하는 구조라서 기존의 TLS 동작 구조로 충분하며, 그래서 OpenSSL을 잘 사용한다.
VPP에 얼마 전에 TLS 계층이 플러그인 형태로 추가됐다. 기반 라이브러리로 OpenSSL이나 mbed TLS를 사용할 수 있으며 일종의 메모리 BIO를 쓴다. 재밌게도 OpenSSL 비동기 동작 지원 코드도 있다. 주기적으로 암호 장치 폴링을 하는 입력 노드를 추가한다.
이전 글에서 다룬 것처럼 리눅스 커널에도 TLS (레코드 계층) 구현체가 있다. 3월 말에 수신부까지 구현되고 송신 쪽에 한해서 암호 연산 하드웨어(Mellanox NIC) 지원까지 추가됐다. 자잘한 볼거리들이 있기는 하지만 위로 제공하는 인터페이스가 소켓 API라서 동작 구조 면에선 특별한 게 없다.
Node.js에 TLS 모듈이 있다. 이벤트와 콜백이 난무하는 프레임워크니까 미는 동작 구조의 TLS 라이브러리가 있다면 잘 어울리겠지만 현재는 OpenSSL을 메모리 BIO로 감싸서 사용한다. Twisted도 마찬가지다.
그 외에 Facebook에서 만들어 내부에서 쓴다는 TLS 1.3 전용 라이브러리 Fizz가 있다. OpenSSL의 libcrypto를 가져다 쓰고 libssl에 해당하는 부분을 구현한다. Future를 이용한 비동기 실행 구조라고 하는데, 복잡하다.
